About 6 years ago I had a conversion experience. This completely changed my world view and opened up new ways of thinking. I am talking about web standards, and my discovery of the work of Jeffrey Zeldman and others at the Web Standards Project.
Like many others at the time I became a zealot for the cause, and this inevitably led me down the path to other standards and the web accessibility initiative.
This all seemed like good sense at the time, and like most good followers of the cause I adhered to the published best practices espoused by the prophets.
Like most people, this is how I ran my web projects:
1. Specify the accessibility standards that have to be met (internally or by a contractor).
2. Schedule a testing phase at some point prior to launch, and perhaps commission a report.
3. Fix the things that didn't meet the standard, and;
4. Launch the site.
5. Job done.
Sadly, once any site is launched the second law of thermodynamics begins to do its work. This law states that all closed systems (those that don't have more energy applied to them from outside) tend to return to a state of chaos. Does that sound like most websites?
Without constant vigilance content becomes less relevant (or wrong), and markup gets less valid over time. From an accessibility point of view, attention to the details that matter (e.g. access keys, hidden headings, and general markup) will also tend to disperse, making for an inconsistent experience.
After the fourth iteration of the RNZ site was launched (the one you see today) I realised that we'd been doing things differently. No longer did we simply follow the 'recipes' advocated by others; those practices had become a way of life and we were developing our own ways of doing things. New content areas were being created, and we were thinking about accessibility issues without thinking about them. I thought we had accessibility sussed.
But earlier this year I got some feedback that completely changed my view. Someone had attended a session on screen readers run by the Royal NZ Foundation of the Blind, and had blogged about one small problem with our site. I was mortified. A problem with OUR site?
The problem was that links in the Features section of the home page did not make sense to screen readers. The links following each feature had the text "Find out more", and a screen reader navigating the page would hear a series of links read thus:
link: Find out more
link: Find out more
link: Find out more
Not very helpful, so we added hidden text to each link:
Find out more about Podcast Classics
Find out more about Enzology
The extra text sits in span with a CSS class that removes it from the visual layout.
We've made the use of hidden text standard practice on the site. There are already many hidden headings to say what each section of the page is for: Main navigation list, current location in site, Menu, secondary navigation, and so on, so this was a simple change.
This was a wake up call for me, and highlights a reality: your accessibility effort is never complete.
For our next project Radio NZ is developing a Javascript framework to use as the basis of a new audio player. Our aim is to make something that is simple to use and is highly accessible for those with screen readers. This will be free software and is being developed as an open source project so others can use what we build and contribute.
A few weeks ago I subscribed to the Assistive Technology Interest Group run by the Royal NZ Foundation of the Blind. I did this to enlist the help of the community who'd have to use the player, and for whom it is probably most important to get it right.
One of the benefits of going direct (instead of commissioning a report) is that a conversation can develop. The player can (and will) be fine-tuned through many iterations based on the detailed feedback that comes from talking with people. Compared with the usual build it, test it, fix it approach, I think this process will create a better outcome for everyone.
I have been humbled by the helpfulness of people on the list, and their willingness to explain things that are obvious to them, but not to me. I have also benefited from reading conversations about other access issues.
While on the list I've found that the community is changing all the time - for example new technologies like ARIA are being developed and implemented. People are finding better ways to do things. My expectations of what can now be achieved have gone up.
Where to from here ?
My experience has raised some interesting questions. Why is it that most web projects to do not talk directly to their end users? Or if they do, it is via a third party?
If you were born in or before the 60s think back to when you were a child and see if this rings true. Recall the times when you ever saw a person with a disability in the street. You'd never seen anyone like this before, and being curious, you take a good look. Your parent sees you looking and tells you not to stare. For my generation disability was a thing you hid away and did not discuss.
I shared these thoughts at a recent talk I gave, and there were a lot of heads nodding. For the response I got, I suspect that may people don't engage with the disabled because they are embarrassed and have no idea where to start.
I was talking this over with my wife (a teacher) and she pointed out that while that may be true for our generation (born early 60s), our children (born in the 90s) do not have this problem. The disabled are not hidden away, but attend the same schools as everyone else. They have the same opportunities. There is a different view of 'normal'.
This might be the reason why my generation is less willing to engage with the disabled, and will hire a consultant instead.
That is not to say that you should not hire a consultant; a good one will guide you through the process of making your site accessible, and help you put in place systems to ensure it stays that way. A great consultant will help you to communicate with you end-users on an on-going basis.
To summarise: accessibility is not an box to tick. It is not an event. It is not even a process. It is a conversation, a conversation that has to involve those whom your site exists to serve.
If you have never spent time with people who use assistive technologies to access your site, now is the time to start.
Tuesday, December 16, 2008
Tuesday, December 9, 2008
Follow the mouse cursor with jQuery
At the moment on Radio New Zealand This Way Up is running a feature on keeping bees in your backyard. One of the ideas our web producer Dempsey Woodley came up with for the Bee pages was a bee chasing the cursor around the screen.
The pair of us hunted for code to do this, but most of it seems to have been designed when Netscape 4 was still a dominant force in the browser market. The web also seems to have moved on from such effects.
The first couple Dempsey tried locked the bee image to the cursor, and did not really give a sense of being chased. Then he found the Mouse Squidie effect from Javascript-FX. Perfect.
Two problems though - it did not work in IE 6+, and was not configurable without hacking into the code.
So I have rewritten the thing from scratch based on the original algorithm, and using jQuery to replace the old library functions. I also added a bunch of configuration options so that the effect can be fine tuned.
You can see the new version of the script on the Bee chased page. Like most effects of this type, a little goes a long way.
It's up on github.
The pair of us hunted for code to do this, but most of it seems to have been designed when Netscape 4 was still a dominant force in the browser market. The web also seems to have moved on from such effects.
The first couple Dempsey tried locked the bee image to the cursor, and did not really give a sense of being chased. Then he found the Mouse Squidie effect from Javascript-FX. Perfect.
Two problems though - it did not work in IE 6+, and was not configurable without hacking into the code.
So I have rewritten the thing from scratch based on the original algorithm, and using jQuery to replace the old library functions. I also added a bunch of configuration options so that the effect can be fine tuned.
You can see the new version of the script on the Bee chased page. Like most effects of this type, a little goes a long way.
It's up on github.
Tuesday, November 18, 2008
A Free and Open Source Audio Player
I am proud to announce Radio New Zealand's first free software project.
The project is a set of modular tools that we'll be using to build new audio functionality for the Radio NZ website. The project is hosted on GitHub, which we will use to (we hope) embrace the open source development model.
The first module (available now) is an audio player plugin based on the jQuery JavaScript library, and version 0.1 already has some interesting features.
It can play Ogg files natively in Firefox 3.1 using the audio tag. It can also play MP3s using the same javascript API - you just load a different filename and the player works out what to do. The project includes a basic flash-based MP3 player, and some example code to get you started.
The audio timer and volume readouts for the player are updated via a common set of events, so they work for both types of audio, and you can swap freely between them.
At the moment there is limited error checking, and obviously lots of room for improvements and enhancements.
One of these will be a playlist module, and this is something we are going to fund for our own use.
An interesting angle to the project is that we've already started to talk with the blind community to ensure that the player is usable for people with screen readers. The first phase of this is to test the mark-up for the audio player page to ensure it makes sense.
Phase two will be checking that the basic functionality is simple to use using screen reader and browser hotkeys, and phase three will test playlist manipulation.
I am excited about the project for two reasons. Firstly, we use a lot of free and open source software at Radio NZ, but apart from some bug fixes and minor patches we've not yet been a contributor to the free software commons.
Secondly, I see this as a chance to lift the bar for accessible interface engineering using just HTML and JavaScript. We chose to not use a full flash-based interface - a common approach these days - because it simplifies the building and maintenance of the player to some extent. It also lowers the cost of development, while building on well-understood accessibility techniques.
Let's see how it goes...
The project is a set of modular tools that we'll be using to build new audio functionality for the Radio NZ website. The project is hosted on GitHub, which we will use to (we hope) embrace the open source development model.
The first module (available now) is an audio player plugin based on the jQuery JavaScript library, and version 0.1 already has some interesting features.
It can play Ogg files natively in Firefox 3.1 using the audio tag. It can also play MP3s using the same javascript API - you just load a different filename and the player works out what to do. The project includes a basic flash-based MP3 player, and some example code to get you started.
The audio timer and volume readouts for the player are updated via a common set of events, so they work for both types of audio, and you can swap freely between them.
At the moment there is limited error checking, and obviously lots of room for improvements and enhancements.
One of these will be a playlist module, and this is something we are going to fund for our own use.
An interesting angle to the project is that we've already started to talk with the blind community to ensure that the player is usable for people with screen readers. The first phase of this is to test the mark-up for the audio player page to ensure it makes sense.
Phase two will be checking that the basic functionality is simple to use using screen reader and browser hotkeys, and phase three will test playlist manipulation.
I am excited about the project for two reasons. Firstly, we use a lot of free and open source software at Radio NZ, but apart from some bug fixes and minor patches we've not yet been a contributor to the free software commons.
Secondly, I see this as a chance to lift the bar for accessible interface engineering using just HTML and JavaScript. We chose to not use a full flash-based interface - a common approach these days - because it simplifies the building and maintenance of the player to some extent. It also lowers the cost of development, while building on well-understood accessibility techniques.
Let's see how it goes...
Thursday, November 13, 2008
Equal Height Columns with jQuery
We are about to change to jQuery from Mootools, so I'm in the process of porting our current javascript functions. I'll do a separate post later on why we are changing.
In the meantime here is the code for equal height columns:
Hat tip
In the meantime here is the code for equal height columns:
jQuery.fn.equalHeights=function() {
var maxHeight=0;
this.each(function(){
if (this.offsetHeight>maxHeight) {maxHeight=this.offsetHeight;}
});
this.each(function(){
$(this).height(maxHeight + "px");
if (this.offsetHeight>maxHeight) {
$(this).height((maxHeight-(this.offsetHeight-maxHeight))+"px");
}
});
};It is called like this:$("#cont-pri,#cont-sec,#hleft,#hright,#features,#snw").equalHeights();The jQuery function returns an object containing only the elements found, so you can include identifiers that are not on every page and the function still works. On the RNZ site there are some divs on the home page that do not appear on other pages, but require the equal heights treatment. This means the call above works on any page without generating errors.Hat tip
Friday, November 7, 2008
How to test for audio tag support in your browser
I am writing a small application at the moment that needs audio tag support for Ogg in Firefox 3.1.
The following is the snippet of code I'm using to test this. (I am using the jQuery library).
There may also need to be a check that the browser actually has the codec installed. (Add a comment if this is the case, and I'll update this post when I work out how).
Update (19 Nov 2008): A better way is to add a check for the Mozilla browser into the test. At the moment, Safari has the audio tag, but only supports media types that work in Quicktime.
The following is the snippet of code I'm using to test this. (I am using the jQuery library).
audio_elements = $('audio');
if('volume' in audio_elements[0] ) {
// processing here
}This assumes that there is only one audio element on the page (in my case I dynamically insert one). If the volume property exists, I assume that the element can be used to playback Ogg Vorbis files.There may also need to be a check that the browser actually has the codec installed. (Add a comment if this is the case, and I'll update this post when I work out how).
Update (19 Nov 2008): A better way is to add a check for the Mozilla browser into the test. At the moment, Safari has the audio tag, but only supports media types that work in Quicktime.
if('volume' in audio_elements[0] && $.browser.mozilla)A new function has been added to the HTML5 draft spec - canPlayType() - that gets around these problems.
Thursday, October 23, 2008
Javascript console syntax error on Doctype
I just solved an interesting problem.
There was a Doctype syntax error in the console.
This was caused by an invalid javascript file included on the page - invalid meaning there is no file in the src tag, or the file does not end in .js.
The fix was to remove the CMS code that was inserting an empty javascript tag with no src file.
Tricky to track down, simple to fix.
There was a Doctype syntax error in the console.
This was caused by an invalid javascript file included on the page - invalid meaning there is no file in the src tag, or the file does not end in .js.
The fix was to remove the CMS code that was inserting an empty javascript tag with no src file.
Tricky to track down, simple to fix.
Monday, October 20, 2008
Converting from CVS or SVN to Git
This post is a collection of notes about moving from CVS or Subversion (SVN) to Git.
Over the last 9 months all my projects have moved to Git. Previously I've used SVN, but found creating and merging branches (which in theory looks like the Right Way to Work) to be pretty painful.
Imagine that you have 10 developers working on a project in CVS/SVN. A typical workflow is as follows:
1. A new set of features is assigned to 5 of the programmers. The other 5 are working on bug fixes.
2. Each programmer checks out the current head of the trunk and starts work on their bug or feature.
3. Everyone works on code locally until their work is complete, but NO-ONE commits anything as they work, because that would put the head in an unstable state. Work is only committed when it is complete.
4. The first bug fix is complete and is committed.
5. The first feature is committed.
6. Unit tests are run, and all seems well.
7. The second bug fix is committed.
8. The second feature is committed.
9. The unit tests fail horribly and the application appears to be broken in 10 places.
10. The four programmers who made the last 4 commits have a meeting to see what went wrong. As a result the head is frozen while one of them works out how to fix all the problems.
11. While the head is frozen, everyone else continues to code against the checkout they have (now 4 commits ago) while the current batch of problems are sorted out.
12. The code at the head is fixed, and the next feature is committed.
13. This feature causes more unit tests to fail, and re-breaks 3 of the bugs that have just been fixed.
14. The head is frozen again while the current crop of bugs are fixed.
The above is a amalgam of stories I have heard, and appears to be quite typical in many shops using CVS/SVN.
There are many negative things about this workflow:
1. When features and bugs are committed, they can create more bugs if they clash with other features that have already landed on the trunk.
2. Commits can cause complex bugs because of amount of code in a commit is large.
3. All the work that went into a bug or feature is contained in one commit. If a feature took 5 days of work, this is a lot of change for a commit and can make it harder to identify the point that something when wrong.
4. The inability to commit (i.e. save) work in progress tends to reduce experimentation.
There is also the problem of merging. Nearly everyone I know says that it takes a lot of time to plan a merge, and in practice many people avoid branching as a result.
Source code management systems should not create extra work.
While on a branch, the programmer can make commits as they work. They can branch from the branch to try an experiment. They can roll-back to any previous state. They can even go back to the trunk (master) and do a quick bug fix, before returning to their current work.
The whole point of source code management is to capture work in a progressive manner at a granularity that is useful for understanding the evolution of a feature, and to help in tracking bugs down. (The bisect feature in Git is great to find the point where code broke).
When the new feature is complete, the programmer can rebase their work off the head of the master branch (the trunk). A rebase takes the current (feature) branch and all its commits and moves it to somewhere else. If you rebase a branch off the main truck of code, it is the same as if you had made the branch off the current head, rather than 20 commits back, which is where you started.
This enables local testing to take place just before the new feature is merged back into the trunk.
Practically speaking, a programmer making a new feature would do the following. I'll include the Git commands required, and I'll assume that the programmer already has a local copy of a remote master repository.
1. Create a new branch
git checkout -b new-feature
(-b creates the named branch)
2. Start work. Create a new function as part of the feature. Commit the function.
git commit -m "This function is to add some stuff to blah"
3. Rebase (the master branch has had 3 commits since work started).
To do this they switch back to master
git checkout master
Then changes from the master repository are pulled and merged locally.
git pull
Then checkout the feature branch
git checkout new-feature
The rebase it.
git rebase master
(There are faster ways using fewer commands to do this, but I have broken it out so you can follow the logic.)
4. The programmer then runs locally the unit test for the module he is working on.
5. The unit test fails. Because the change made in the commit is quite small it takes only a few minutes to find the problem. The bug is fixed and committed.
git commit -m "Fixed bug caused by changes in module Y"
6. The cycle above continues until the feature is done.
7. The programmer then switches back to the master branch
git checkout master
8. And merges in the changes.
git merge new-feature
9. All unit tests are then run locally. The code passes so the changes can be pushed to the main repository.
git push
The main repository now has the new feature, AND any other changes committed by other programmers, and assuming they used the same process, the HEAD is now in a working condition.
The git workflow avoids all of the problems that arise from working in isolation, and the single large commits. It allow much greater flexibility to experiment, and to test changes against the current trunk at any stage.
It also means that the evolution of all features is available in the repository.
The slow way is to use an adaptor like cvsimport or git-svn.
Personally, I would recommend cold-turkey.
Migration to a remote server
Project and server migration
Linus Torvalds on Git
In this video Linus Torvalds explains the rationale behind Git, and why the distributed model works better than other models.
Randal Schwartz on Git
Randal Schwartz explains the inner workings of Git.
Git with Rails
Ryan Bates shows how to use Git with a simple rails project. This is useful to see how easy it is to use.
On OSX
On Windows
There is also a guide for svn deserters.
Those of you who are used to CVS/SVN may not see the point of the second of these; once you start using Git you will be making and merging branches all over the place, and the prompt is a great reminder of where you are. The prompt that comes with Git also shows when you are part way through a merge or rebase (i.e. you have unresolved conflicts).
You can use gitk to view the repository (or gitx for OSX).
If there are other resources that readers find useful put them in the comments and I'll add them to this post.
Over the last 9 months all my projects have moved to Git. Previously I've used SVN, but found creating and merging branches (which in theory looks like the Right Way to Work) to be pretty painful.
Why Change ?
"If it ain't broke don't fix it" is the most common reason to not change, closely followed by the lost productivity during the change over. Even given these factors, if you closely examine the workflow that older repositories force business into, the benefits of change become obvious.Imagine that you have 10 developers working on a project in CVS/SVN. A typical workflow is as follows:
1. A new set of features is assigned to 5 of the programmers. The other 5 are working on bug fixes.
2. Each programmer checks out the current head of the trunk and starts work on their bug or feature.
3. Everyone works on code locally until their work is complete, but NO-ONE commits anything as they work, because that would put the head in an unstable state. Work is only committed when it is complete.
4. The first bug fix is complete and is committed.
5. The first feature is committed.
6. Unit tests are run, and all seems well.
7. The second bug fix is committed.
8. The second feature is committed.
9. The unit tests fail horribly and the application appears to be broken in 10 places.
10. The four programmers who made the last 4 commits have a meeting to see what went wrong. As a result the head is frozen while one of them works out how to fix all the problems.
11. While the head is frozen, everyone else continues to code against the checkout they have (now 4 commits ago) while the current batch of problems are sorted out.
12. The code at the head is fixed, and the next feature is committed.
13. This feature causes more unit tests to fail, and re-breaks 3 of the bugs that have just been fixed.
14. The head is frozen again while the current crop of bugs are fixed.
The above is a amalgam of stories I have heard, and appears to be quite typical in many shops using CVS/SVN.
There are many negative things about this workflow:
1. When features and bugs are committed, they can create more bugs if they clash with other features that have already landed on the trunk.
2. Commits can cause complex bugs because of amount of code in a commit is large.
3. All the work that went into a bug or feature is contained in one commit. If a feature took 5 days of work, this is a lot of change for a commit and can make it harder to identify the point that something when wrong.
4. The inability to commit (i.e. save) work in progress tends to reduce experimentation.
There is also the problem of merging. Nearly everyone I know says that it takes a lot of time to plan a merge, and in practice many people avoid branching as a result.
Source code management systems should not create extra work.
The Git Workflow
Contrasting the above, Git allows for simple branching and merging, making it trivial to work on new features and bugs in a temporary branch. It also makes it simpler to manage existing stable, development and maintenance branches.While on a branch, the programmer can make commits as they work. They can branch from the branch to try an experiment. They can roll-back to any previous state. They can even go back to the trunk (master) and do a quick bug fix, before returning to their current work.
The whole point of source code management is to capture work in a progressive manner at a granularity that is useful for understanding the evolution of a feature, and to help in tracking bugs down. (The bisect feature in Git is great to find the point where code broke).
When the new feature is complete, the programmer can rebase their work off the head of the master branch (the trunk). A rebase takes the current (feature) branch and all its commits and moves it to somewhere else. If you rebase a branch off the main truck of code, it is the same as if you had made the branch off the current head, rather than 20 commits back, which is where you started.
This enables local testing to take place just before the new feature is merged back into the trunk.
Practically speaking, a programmer making a new feature would do the following. I'll include the Git commands required, and I'll assume that the programmer already has a local copy of a remote master repository.
1. Create a new branch
git checkout -b new-feature
(-b creates the named branch)
2. Start work. Create a new function as part of the feature. Commit the function.
git commit -m "This function is to add some stuff to blah"
3. Rebase (the master branch has had 3 commits since work started).
To do this they switch back to master
git checkout master
Then changes from the master repository are pulled and merged locally.
git pull
Then checkout the feature branch
git checkout new-feature
The rebase it.
git rebase master
(There are faster ways using fewer commands to do this, but I have broken it out so you can follow the logic.)
4. The programmer then runs locally the unit test for the module he is working on.
5. The unit test fails. Because the change made in the commit is quite small it takes only a few minutes to find the problem. The bug is fixed and committed.
git commit -m "Fixed bug caused by changes in module Y"
6. The cycle above continues until the feature is done.
7. The programmer then switches back to the master branch
git checkout master
8. And merges in the changes.
git merge new-feature
9. All unit tests are then run locally. The code passes so the changes can be pushed to the main repository.
git push
The main repository now has the new feature, AND any other changes committed by other programmers, and assuming they used the same process, the HEAD is now in a working condition.
The git workflow avoids all of the problems that arise from working in isolation, and the single large commits. It allow much greater flexibility to experiment, and to test changes against the current trunk at any stage.
It also means that the evolution of all features is available in the repository.
How to Change to Git
There are two ways: cold turkey or slowly. If you go cold-turkey it has to be on a new project (easy), or you have to convert your old repository (harder).The slow way is to use an adaptor like cvsimport or git-svn.
Personally, I would recommend cold-turkey.
SVN Cold Turkey Links
Basic MigrationMigration to a remote server
Project and server migration
CVS Cold-Turkey Links
CVS to Git transition guideUnderstanding Git
I'd recommend watching the following videos before starting to use git.Linus Torvalds on Git
In this video Linus Torvalds explains the rationale behind Git, and why the distributed model works better than other models.
Randal Schwartz on Git
Randal Schwartz explains the inner workings of Git.
Git with Rails
Ryan Bates shows how to use Git with a simple rails project. This is useful to see how easy it is to use.
Installing Git
On GNU/Linux (from source)On OSX
On Windows
Learning Git
To learn how to use git, the best videos around are on gitcasts. To get started view the first 4 videos in the basic usage section.There is also a guide for svn deserters.
Tools to help using Git
The best tools are built right in, you just have to know where to find them. My personal favourites are command line auto-completion and showing the branch in the prompt. I have blogged about this previously.Those of you who are used to CVS/SVN may not see the point of the second of these; once you start using Git you will be making and merging branches all over the place, and the prompt is a great reminder of where you are. The prompt that comes with Git also shows when you are part way through a merge or rebase (i.e. you have unresolved conflicts).
You can use gitk to view the repository (or gitx for OSX).
If there are other resources that readers find useful put them in the comments and I'll add them to this post.
Thursday, September 25, 2008
Native Ogg playback with Firefox 3.1
I have added a new Javascript function to the Radio NZ site called Oggulate.
This function parses through pages that have Ogg download links and replaces them with a Play/Pause button. The button plays (and pauses) the Ogg file using Firefox 3.1's built in support for Ogg Vorbis.
The Oggulator can be activated by installing a small bookmarklet:
javascript:oggulate();
Clicking on the bookmarklet runs the function and gives you a nice page full of buttons to play Ogg. You will need one of the latest Firefox 3.1 builds for this to work.
The functionality in the script is rudimentary, and 3.1 is still in development, so don't expect it to be perfect. (I notice there is often a delay before playback starts for the first clip you play on a page, and I have had a few crashes and lock-ups).
This feature of the RNZ site is experimental at the moment, so I'm not able to offer support. It is primarily so people can test Firefox.
If anyone wants to add features or improve the function, I'll upload it (after reviewing the changes) so everyone can access them. webmaster at radionz dot co dot nz.
(NB: As at 2013 this feature is no longer supported.)
This function parses through pages that have Ogg download links and replaces them with a Play/Pause button. The button plays (and pauses) the Ogg file using Firefox 3.1's built in support for Ogg Vorbis.
The Oggulator can be activated by installing a small bookmarklet:
javascript:oggulate();
Clicking on the bookmarklet runs the function and gives you a nice page full of buttons to play Ogg. You will need one of the latest Firefox 3.1 builds for this to work.
The functionality in the script is rudimentary, and 3.1 is still in development, so don't expect it to be perfect. (I notice there is often a delay before playback starts for the first clip you play on a page, and I have had a few crashes and lock-ups).
This feature of the RNZ site is experimental at the moment, so I'm not able to offer support. It is primarily so people can test Firefox.
If anyone wants to add features or improve the function, I'll upload it (after reviewing the changes) so everyone can access them. webmaster at radionz dot co dot nz.
(NB: As at 2013 this feature is no longer supported.)
Wednesday, September 10, 2008
Clearing the Cache on Matrix
Here's the problem:
We run a master/slave server pair. Each has a web server and database server. The master is accessed via our intranet, and is where we do all our editing and importing of content. This is replicated to the public slave servers.
The slave server has a Squid reverse proxy running in front of it to cushion the site against large peaks in traffic. These peaks occur when our on-air listeners are invited to go to the site to get some piece of information related to the current programme. The cache time in Matrix (and therefore in Squid) is 20 minutes.
The database is replicated with Slony, while the filesystems is syncronised with a custom tool based on rsync.
If we update content it can take up to 20 minutes for that content to show on the public side of the site. This is a problem when we want to do fast updates, especially for news content.
We've looked at a number of solutions, but none quite do what we wanted.
In a stand-alone (un-replicated) system clearing the cache is simple. There is a trigger in Matrix called Set Cache Expiry, that allows you to expire the Matrix cache early. This works OK on a single server system but not if you have a cluster and use Squid. The main issue in that case is that even though the trigger is syncronous, the clearing is not. If Slony has a lot of work to do, there is still a chance that the expiry date has passed before the asset is actually updated on the slave.
A clearing system needs to be 100% predictable, which led me to devise an alternative solution.
We needed to do three things:
a) Determine when changes made on the Master have been replicated to the Slave.
b) Collect ids of assets that are changed and the pages they appear on.
c) Clear the assets collected in b) when we know a).
This is how we do it.
a) There are two queries that can be run on the Master database to get this information:
psql -U postgres -h server_name db_name -qAtc "SELECT st_last_event FROM _replication.sl_status"
returns a sequence number which represent where the Slony master is currently at.
psql -U postgres -h server_name db_name -qAtc "SELECT st_last_received FROM _replication.sl_status
returns the sequence number where the slave is up to.
If you grab the master sequence number after a content change (a database query), you can tell when that change has reached the slave when it's sequence number is the same or greater.
b) We have a script that imports news items to matrix. One of the attributes in the imported data is a list of asset ids that are affected by the import action. We know in advance what asset lists and pages the content will show on.
When the script runs it collects these for each imported asset, and compiles a list of asset ids (with no duplicates).
c) This is how it is bolted together.
After some assets have been imported, the import script calls a second script which adds the items to a queue:
system( 'perl add_to_cache_queue.pl --assets="' . $asset_list . '"' );
This script is short, so I'll reproduce it here.
The queue itself is Perl's IPC::DirQueue, a very cool module for managing a filesystem-based queue.
When an item is found on the queue it checks the Slony sequence number that was saved with the data. If the number has passed on the slave, then yet another script is run, but this time on the slave (public) server.
php ./matrixFlushCache.php --site="/path/to/site/radionz" --assets="comma_sep_list"
This last script resolves the asset id numbers in Matrix to a list of file system cache buckets and URLs. The cache buckets are removed, and the URLs are also cleared from the Squid cache. The cache is them primed with the new page. The script was written by Colin Macdonald.
This is what the output looks like:
** lock gained Sat Aug 30 20:03:01 2008 running jobs: * * * * ?
Slony slave is at 485328, Got a job at: 485327
data:200,1585920,1584495,764616,etc
Clearing cache for #200
Unlinking cache/1313/e8f12c0d7b5889d748872bdad215c0cf
Unlinking cache/1113/aaa1666c26af81a0b044ab2fecb950ae
Deleting DB records (2 reported, 2 deleted)
.
snip a bunch of the same but for different assets.
.
Refreshing urls:
http://www.radionz.co.nz/ ... 200
http://www.radionz.co.nz/home ... 200
http://www.radionz.co.nz/news/business ... 200
http://www.radionz.co.nz/news/business/ ... Skipped
snip a bunch of URLs
- lock released
The script is looping and checking every three seconds for a new job (queued asset ids to clear). The * means it checked for a queued job and none was found. The ? means that a job was found but that the slave had a lower sequence number than the one stored with the job.
The top 5 stories (the ones on the home page) are also cleared and refreshed.
The Flush cache has a URL filter so you can exclude certain URLs from being flushed - an example is the query ridden script kiddie hacks that people try to run against sites. There is no point in re-caching those.
Another is URLs ending in /. In our case this mostly means the someone has deleted the story off the end of the URLs to see what they get, so there is no reason to refresh these either.
A feature that I'm working on will clear just the Matrix and Squid caches for the non-front page stories. These all have a 2 minute expiry time and if we expire all the caches the end user will re-prime the cache. There is no performance hit in doing this as the browser and squid come back for these pages every two minutes anyway.
The system I have just outlined allows us to remotely add and update items in Matrix and for those changes to appear on the site within 5 minutes. I hope someone finds this useful.
We run a master/slave server pair. Each has a web server and database server. The master is accessed via our intranet, and is where we do all our editing and importing of content. This is replicated to the public slave servers.
The slave server has a Squid reverse proxy running in front of it to cushion the site against large peaks in traffic. These peaks occur when our on-air listeners are invited to go to the site to get some piece of information related to the current programme. The cache time in Matrix (and therefore in Squid) is 20 minutes.
The database is replicated with Slony, while the filesystems is syncronised with a custom tool based on rsync.
If we update content it can take up to 20 minutes for that content to show on the public side of the site. This is a problem when we want to do fast updates, especially for news content.
We've looked at a number of solutions, but none quite do what we wanted.
In a stand-alone (un-replicated) system clearing the cache is simple. There is a trigger in Matrix called Set Cache Expiry, that allows you to expire the Matrix cache early. This works OK on a single server system but not if you have a cluster and use Squid. The main issue in that case is that even though the trigger is syncronous, the clearing is not. If Slony has a lot of work to do, there is still a chance that the expiry date has passed before the asset is actually updated on the slave.
A clearing system needs to be 100% predictable, which led me to devise an alternative solution.
We needed to do three things:
a) Determine when changes made on the Master have been replicated to the Slave.
b) Collect ids of assets that are changed and the pages they appear on.
c) Clear the assets collected in b) when we know a).
This is how we do it.
a) There are two queries that can be run on the Master database to get this information:
psql -U postgres -h server_name db_name -qAtc "SELECT st_last_event FROM _replication.sl_status"
returns a sequence number which represent where the Slony master is currently at.
psql -U postgres -h server_name db_name -qAtc "SELECT st_last_received FROM _replication.sl_status
returns the sequence number where the slave is up to.
If you grab the master sequence number after a content change (a database query), you can tell when that change has reached the slave when it's sequence number is the same or greater.
b) We have a script that imports news items to matrix. One of the attributes in the imported data is a list of asset ids that are affected by the import action. We know in advance what asset lists and pages the content will show on.
When the script runs it collects these for each imported asset, and compiles a list of asset ids (with no duplicates).
c) This is how it is bolted together.
After some assets have been imported, the import script calls a second script which adds the items to a queue:
system( 'perl add_to_cache_queue.pl --assets="' . $asset_list . '"' );
This script is short, so I'll reproduce it here.
#!/usr/local/bin/perlA second script runs on the machine as a worker process, watching the queue. This uses the loop code I outlined in my last post.
# This script is used to add items to the DirQueue on the current machine
# it is for testing purposes
use strict;
use Getopt::Long;
use DirQueue;
use lib ".";
my $assets_to_clear = '';
GetOptions( "assets=s" => \$assets_to_clear );
if( $assets_to_clear eq '' ){
exit(1);
}
my $command = 'psql -U postgres -h host db -qAtc "SELECT st_last_event FROM _replication.sl_status"';
my $last_event = `$command`;
$last_event =~ s/\n//;
print "Last event: $last_event\n";
# a queue to add items to. Locks can last for 2 minutes
my $string = " this is a test string add to the file at " . time ."\n";
my $dq = DirQueue->new({ dir => "matrix-cache-queue",data_file_mode => 0777, active_file_lifetime => 120 });
if( $dq->enqueue_string ($assets_to_clear, { 'id' => $last_event, 'time' => localtime(time)} ) ){
exit 0;
}
print "could not queue file";
exit 1;
The queue itself is Perl's IPC::DirQueue, a very cool module for managing a filesystem-based queue.
When an item is found on the queue it checks the Slony sequence number that was saved with the data. If the number has passed on the slave, then yet another script is run, but this time on the slave (public) server.
php ./matrixFlushCache.php --site="/path/to/site/radionz" --assets="comma_sep_list"
This last script resolves the asset id numbers in Matrix to a list of file system cache buckets and URLs. The cache buckets are removed, and the URLs are also cleared from the Squid cache. The cache is them primed with the new page. The script was written by Colin Macdonald.
This is what the output looks like:
** lock gained Sat Aug 30 20:03:01 2008 running jobs: * * * * ?
Slony slave is at 485328, Got a job at: 485327
data:200,1585920,1584495,764616,etc
Clearing cache for #200
Unlinking cache/1313/e8f12c0d7b5889d748872bdad215c0cf
Unlinking cache/1113/aaa1666c26af81a0b044ab2fecb950ae
Deleting DB records (2 reported, 2 deleted)
.
snip a bunch of the same but for different assets.
.
Refreshing urls:
http://www.radionz.co.nz/ ... 200
http://www.radionz.co.nz/home ... 200
http://www.radionz.co.nz/news/business ... 200
http://www.radionz.co.nz/news/business/ ... Skipped
snip a bunch of URLs
- lock released
The script is looping and checking every three seconds for a new job (queued asset ids to clear). The * means it checked for a queued job and none was found. The ? means that a job was found but that the slave had a lower sequence number than the one stored with the job.
The top 5 stories (the ones on the home page) are also cleared and refreshed.
The Flush cache has a URL filter so you can exclude certain URLs from being flushed - an example is the query ridden script kiddie hacks that people try to run against sites. There is no point in re-caching those.
Another is URLs ending in /. In our case this mostly means the someone has deleted the story off the end of the URLs to see what they get, so there is no reason to refresh these either.
A feature that I'm working on will clear just the Matrix and Squid caches for the non-front page stories. These all have a 2 minute expiry time and if we expire all the caches the end user will re-prime the cache. There is no performance hit in doing this as the browser and squid come back for these pages every two minutes anyway.
The system I have just outlined allows us to remotely add and update items in Matrix and for those changes to appear on the site within 5 minutes. I hope someone finds this useful.
Friday, August 29, 2008
Opening up old content and more Ogg Vorbis
Just today we completed work on the Saturday Morning with Kim Hill programme archive.
This opens up all the content that has been broadcast on the show since the start of the year.
All audio can be downloaded in MP3 format, and in Ogg Vorbis since August. The programme archive page lists a summary of all programmes, and you can also search audio and text.
Morning Report and Nine To Noon now have Ogg Vorbis, and I expect to be able to open up their older content in the next few weeks.
Other programmes will have Ogg Vorbis added as I have time.
I have a test RSS feed (the URL might change) with Ogg enclosures for Saturday Morning. Send any feedback to webmaster at radionz dot co dot nz.
This opens up all the content that has been broadcast on the show since the start of the year.
All audio can be downloaded in MP3 format, and in Ogg Vorbis since August. The programme archive page lists a summary of all programmes, and you can also search audio and text.
Morning Report and Nine To Noon now have Ogg Vorbis, and I expect to be able to open up their older content in the next few weeks.
Other programmes will have Ogg Vorbis added as I have time.
I have a test RSS feed (the URL might change) with Ogg enclosures for Saturday Morning. Send any feedback to webmaster at radionz dot co dot nz.
Wednesday, August 27, 2008
Creating a Pseudo Daemon Using Perl
One of the trickier software jobs I've worked on is a Perl script that runs almost continuously.
The script was needed to check a folder for new content (in the form of news stories) and process them.
The stories are dropped into a folder as a group via ftp, and the name of each story is written into a separate file. The order in this file is the order the stories need to appear on the website.
The old version of the script ran by cron every minute, but there were three problems.
The first is that you might have to wait a whole minute for content to be processed, which is not really ideal for a news service.
The second is that should the script be delayed for some reason, it is possible to end up with a race condition with two (or more scripts) trying to process the same content.
The third is that the script could start reading the order file before all the files were uploaded.
In practice 2 and 3 were very rare, but very disruptive when they did occur. The code needed to avoid both.
The new script is still run once per minute via cron, but contains a loop which allows it to check for content every three seconds.
It works this way:
1. When the script starts it grabs the current time and tries to obtain an exclusive write lock on a lock file.
2. If it gets the lock it starts the processing loop.
3. When the order file is found the script waits for 10 seconds. This is to allow any current upload process to complete.
4. It then reads the file, deletes it, and starts processing each of the story files.
5. These are all written out to XML (which is imported into the CMS), and the original files are deleted.
6. When this is done, the script continues to look for files until 55 seconds have elapsed since it started.
7. When no time is left it exits.
This is what the loop code looks like:
This is the output of the script (each number is the name of a job - we have three jobs, each for one ftp directory:
You can see that the script found some content part way through its cycle, and ran over the allotted time, so the next run of the script did not get a full minute to run.
This ensures that there is never a race between two scripts. You can see next happens when a job take more than 2 minutes:
All the scripts that were piling up waiting to get the lock exited immediately, once they found that there time was up.
I am using the same looping scheme to process a queue elsewhere in our publishing system and I'll explain this in my next post.
The script was needed to check a folder for new content (in the form of news stories) and process them.
The stories are dropped into a folder as a group via ftp, and the name of each story is written into a separate file. The order in this file is the order the stories need to appear on the website.
The old version of the script ran by cron every minute, but there were three problems.
The first is that you might have to wait a whole minute for content to be processed, which is not really ideal for a news service.
The second is that should the script be delayed for some reason, it is possible to end up with a race condition with two (or more scripts) trying to process the same content.
The third is that the script could start reading the order file before all the files were uploaded.
In practice 2 and 3 were very rare, but very disruptive when they did occur. The code needed to avoid both.
The new script is still run once per minute via cron, but contains a loop which allows it to check for content every three seconds.
It works this way:
1. When the script starts it grabs the current time and tries to obtain an exclusive write lock on a lock file.
2. If it gets the lock it starts the processing loop.
3. When the order file is found the script waits for 10 seconds. This is to allow any current upload process to complete.
4. It then reads the file, deletes it, and starts processing each of the story files.
5. These are all written out to XML (which is imported into the CMS), and the original files are deleted.
6. When this is done, the script continues to look for files until 55 seconds have elapsed since it started.
7. When no time is left it exits.
This is what the loop code looks like:
my $stop_time = time + 55;
my $loop = 1;
my $locking_loop = 1;
my $has_run = 0;
while( $locking_loop ){
# first see if there is a lock file and
# wait till the other process is done if there is
if( open my $LOCK, '>>', 'inews.lock' ){
flock($LOCK, LOCK_EX) or die "could not lock the file";
print "** lock gained " . localtime(time) . " running jobs: " if ($debug);
while( $loop ){
my $job_count = keys(%jobs);
for my $job (1..$job_count){
# run the next job if we are within the time limit
if( time < $stop_time ){ $has_run ++; print "$job "; process( $job ); sleep(3); } else{ $loop = 0; $locking_loop = 0; } } } close $LOCK; print "- lock released\n" } else{ print "Could not open lock file for writing\n"; $locking_loop = 0; # nothing happens here } unless($has_run){ print localtime(time) . " No jobs processed\n" } }
This is the output of the script (each number is the name of a job - we have three jobs, each for one ftp directory:
** lock gained Tue Jul 22 08:17:00 2008running jobs:1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 - lock released
** lock gained Tue Jul 22 08:18:00 2008 running jobs: 1 2 3 1 2 3 1 2 3 1
24 news files to process
* Auditor-General awaits result of complaint about $100,000 donation
* NZ seen as back door entry to Australia
.
snip
.
- lock released
** lock gained Tue Jul 22 08:19:23 2008 running jobs: 1 2 3 1 2 3 1 2 3 1 2 - lock released You can see that the script found some content part way through its cycle, and ran over the allotted time, so the next run of the script did not get a full minute to run.
This ensures that there is never a race between two scripts. You can see next happens when a job take more than 2 minutes:
- lock released
** lock gained Tue Jul 22 10:46:32 2008 running jobs: - lock released
Tue Jul 22 10:46:32 2008 No jobs processed
** lock gained Tue Jul 22 10:46:32 2008 running jobs: - lock released
Tue Jul 22 10:46:32 2008 No jobs processed
** lock gained Tue Jul 22 10:46:32 2008 running jobs: - lock released
Tue Jul 22 10:46:32 2008 No jobs processed
** lock gained Tue Jul 22 10:46:32 2008 running jobs: 1 2 3 1 2 3 1 2All the scripts that were piling up waiting to get the lock exited immediately, once they found that there time was up.
I am using the same looping scheme to process a queue elsewhere in our publishing system and I'll explain this in my next post.
Friday, August 15, 2008
Using Git to manage rollback on dynamic websites
Page rollback is useful for archival and legal reasons - you can go back and see a page's contents at any point in time. It is also a life-saver if some important content gets accidentally updated - historical content is just a cut and paste away. The MediaWiki software the runs Wikipedia is a good example of a system with rollback.
There are several methods available to a programmer wanting to enable a rollback feature on a Content Management System.
The simplest way to do this is store a copy of every version of the saved page, and maintain a list of pointers to the most recent pages. It would also be possible to store diffs in the database - old versions are saved as a series of diffs against the current live page.
A useful feature would be the ability to view a snapshot of the entire site at any point in time. This is probably of greatest interest to state-owned companies and Government departments who need to comply with legislation like New Zealand's Public Records Act.
A database-based approach would be resource intensive - you'd have to get all the required content, and then there is the challenge to display an alternative version of the site to one viewer while others are still using the latest version.
I was thinking of alternatives to the above, and wondered if a revision control system might be a more efficient way to capture the history, and to allow viewing of the whole site at points in time.
Potentially this scheme could be used with any CMS, so I thought that I'd document it in case someone finds it useful.
Git has several features that might help us out:
Cryptographic authentication
According to the Git site: "The Git history is stored in such a way that the name of a particular revision (a "commit" in Git terms) depends upon the complete development history leading up to that commit. Once it is published, it is not possible to change the old versions without it being noticed. Also, tags can be cryptographically signed."
This is a great choice from a legal perspective.
Small Storage Requirements
Again, from the site: "It also uses an extremely efficient packed format for long-term revision storage that currently tops any other open source version control system".
Josh Carter has some comparisons and so does Pieter de Biebe.
Overall it looks as though Git does the best job of storing content, and because it is only storing changes it'll be more efficient that saving each revision of a page in a database. (Assuming that is how it is done.)
And of course Git is fast, although we are only using commit and checkout in this system.
Wiring it Up
To use Git with a dynamic CMS, there would need to a save hook that did the following.
When a page is saved:
1. Get the content from the page being saved and the URL path.
2. Save the content and path (or paths) to a queue.
3. The queue manager would take items off the queue, write them to the file system and commit them.
These commits are on top of an initial save of the whole site, whatever that state may be. The CMS would need a feature that outputs the current site, or perhaps a web crawler could be used.
To view a page in the past, it is a simple matter to checkout the commit you want and view the site as static pages via a web server. Because every commit is built on top of previous changes, the whole site is available as it was when a particular change was made.
The purpose of the queue manager is to allow commits to be suspended so that you can checkout an old page, or for maintenance. Git gc could be run each night via cron while commits were suspended. I'd probably use IPC::DirQueue because it is fast, stable, and allows multiple processes to add items to the queue (and take them off), so there won't be any locking or race issues.
Where the CMS is only managing simple content - that is, there are no complex relationships between assets such as nesting, or sharing of content - this scheme would probably work quite well.
There are problems though when content is nested (embedded) or shared with other pages, or is part of an asset listing (a page that display the content of other items in the CMS).
If an asset is nested inside another asset the CMS would need to know about this relationship. If the nested asset is saved then any assets it appears inside need to be committed too, otherwise the state of content in Git will not reflect what was on the site.
I'd expect a linked tree of content use would be implemented to manage intra-page relationships and provide the information about which pages need to be committed.
This is all theoretical, but feel free to post any comments to extend the discussion.
There are several methods available to a programmer wanting to enable a rollback feature on a Content Management System.
The simplest way to do this is store a copy of every version of the saved page, and maintain a list of pointers to the most recent pages. It would also be possible to store diffs in the database - old versions are saved as a series of diffs against the current live page.
A useful feature would be the ability to view a snapshot of the entire site at any point in time. This is probably of greatest interest to state-owned companies and Government departments who need to comply with legislation like New Zealand's Public Records Act.
A database-based approach would be resource intensive - you'd have to get all the required content, and then there is the challenge to display an alternative version of the site to one viewer while others are still using the latest version.
I was thinking of alternatives to the above, and wondered if a revision control system might be a more efficient way to capture the history, and to allow viewing of the whole site at points in time.
Potentially this scheme could be used with any CMS, so I thought that I'd document it in case someone finds it useful.
Git has several features that might help us out:
Cryptographic authentication
According to the Git site: "The Git history is stored in such a way that the name of a particular revision (a "commit" in Git terms) depends upon the complete development history leading up to that commit. Once it is published, it is not possible to change the old versions without it being noticed. Also, tags can be cryptographically signed."
This is a great choice from a legal perspective.
Small Storage Requirements
Again, from the site: "It also uses an extremely efficient packed format for long-term revision storage that currently tops any other open source version control system".
Josh Carter has some comparisons and so does Pieter de Biebe.
Overall it looks as though Git does the best job of storing content, and because it is only storing changes it'll be more efficient that saving each revision of a page in a database. (Assuming that is how it is done.)
And of course Git is fast, although we are only using commit and checkout in this system.
Wiring it Up
To use Git with a dynamic CMS, there would need to a save hook that did the following.
When a page is saved:
1. Get the content from the page being saved and the URL path.
2. Save the content and path (or paths) to a queue.
3. The queue manager would take items off the queue, write them to the file system and commit them.
These commits are on top of an initial save of the whole site, whatever that state may be. The CMS would need a feature that outputs the current site, or perhaps a web crawler could be used.
To view a page in the past, it is a simple matter to checkout the commit you want and view the site as static pages via a web server. Because every commit is built on top of previous changes, the whole site is available as it was when a particular change was made.
The purpose of the queue manager is to allow commits to be suspended so that you can checkout an old page, or for maintenance. Git gc could be run each night via cron while commits were suspended. I'd probably use IPC::DirQueue because it is fast, stable, and allows multiple processes to add items to the queue (and take them off), so there won't be any locking or race issues.
Where the CMS is only managing simple content - that is, there are no complex relationships between assets such as nesting, or sharing of content - this scheme would probably work quite well.
There are problems though when content is nested (embedded) or shared with other pages, or is part of an asset listing (a page that display the content of other items in the CMS).
If an asset is nested inside another asset the CMS would need to know about this relationship. If the nested asset is saved then any assets it appears inside need to be committed too, otherwise the state of content in Git will not reflect what was on the site.
I'd expect a linked tree of content use would be implemented to manage intra-page relationships and provide the information about which pages need to be committed.
This is all theoretical, but feel free to post any comments to extend the discussion.
Saturday, August 9, 2008
Setting up Ogg Vorbis Coding for MP2 Audio Files
Today on Radio New Zealand National, Kim Hill interviewed Richard Stallman on the Saturday Morning programme. Prior to the interview Richard requested that the audio be made available in Ogg Vorbis format, in addition to whatever other formats we use.
At the moment our publishing system generates audio in Windows Media and MP3 formats, so I had two options: generate the Ogg files by hand on the day, or add an Ogg Vorbis module to do it automatically.
Since the publishing system is based on free software (Perl), it was a simple matter to add a new function to our existing custom transcoder module. It also avoided the task of manually coding and uploading each file. Here is the function:
Once this code was in place, the only other change was to update the master programme data file to switch on the new format.
After that, any audio published to the Saturday programme would automatically get the new file format, and this would also be uploaded to our servers.
The system was originally built with this in mind - add a new type, update the programme data, done - but this is the first time I have used it.
You can see the result on today's Saturday page.
At the moment our publishing system generates audio in Windows Media and MP3 formats, so I had two options: generate the Ogg files by hand on the day, or add an Ogg Vorbis module to do it automatically.
Since the publishing system is based on free software (Perl), it was a simple matter to add a new function to our existing custom transcoder module. It also avoided the task of manually coding and uploading each file. Here is the function:
All the Ogg parameters are hard-coded at this stage, and I'll add code to allow for different rates later, once I have done some tests to see what works best for our purposes.
sub VORBIS()
{
my( $self ) = shift;
my( $type ) = TR_256;
my $inputFile = $self->{'inputFile'};
my $basename = $self->{'basename'};
my $path = $self->{'outputPath'};
my $ext = '.ogg';
my $output_file = "$path\\$basename$ext";
my $lame_decoding_params = " --mp2input --decode $inputFile - ";
my $ogg_encoding_params = qq{ - --bitrate 128 --downmix --quality 2 --title="$self->{'title'}" --artist="Radio New Zealand" --output="$output_file" };
my $command = "lame $lame_decoding_params | oggenc2 $ogg_encoding_params";
print "$command \n" if ($self->{'debug'});
my $R = $rates{$type};
&RunJob( $self, $command, "m$rates{$type}" );
# we must return a code so the caller knows what to do
return 1;
}
Once this code was in place, the only other change was to update the master programme data file to switch on the new format.
After that, any audio published to the Saturday programme would automatically get the new file format, and this would also be uploaded to our servers.
The system was originally built with this in mind - add a new type, update the programme data, done - but this is the first time I have used it.
You can see the result on today's Saturday page.
Monday, July 28, 2008
News Categories at Radio NZ
We've just completed a major update to the news section of the site that allows us to categorise news content.
We use the MySource Matrix CMS, and categorising content is a trivial exercise using the built in asset listing pages. The tricky part in our case is that none of our news staff actually write their content directly in the CMS, or even have logins. Why?
When we first started using Matrix, the system's functionality was much more limited than it is today (in version 3.18.3). For example, paint layouts - which are used to style news items - had not yet been added to the system.
The available features were perfectly suitable for the service that we were able to offer at that time though.
The tool used by our journalists is iNews - a system optimised for processing news content in a large news environment - and it was significantly faster than Matrix for this type of work (as it should be). Because staff were already adept at using it, we decided to use iNews to edit and compile stories and export the result to the CMS.
This would also mean that staff didn't have to know any HTML, and we could add simple codes to the text to allow headings and other basic web formatting. It would also dramatically simplify initial and on-going training.
The proposed process required two scripts. The first script captured the individual iNews stories, ordered them, converted the content to HTML, and packaged them with some metadata into an XML file. (iNews can output a group to stories via ftp with a single command).
The XML was copied to the CMS server where script 2 imported the specified content.

Each block of stories was placed in a folder in the CMS. The most recent folder represented the current publish, and was stamped with the date and time. The import script then changed the settings on the site's home page headline area, the RSS news feed and the News home to list the stories in this new folder.
Stories appeared on the site as they were ordered in the iNews system, and the first five were automatically displayed on the home page.
On the site, story URLs looked like this:
www.radionz.co.nz/news/200807221513/134e5321
and each new publish replaced the any previous versions:
www.radionz.co.nz/news/200807221545/2ed5432
On the technical side, the iNews processing script ran once a minute via a cron job, but over time we found two problems with this approach.
The first was that the URL for a story was not unique over time - each update got a new URL. RSS readers had trouble working our what was new content and not just a new publish of the same story. People linking to a story would get a stale version of the content, depending on when it was actually updated.
The second related to the 1 minute cycle time of the processing script. Most of the time this worked fine, but occasionally we'd get a partial publish when the script started before iNews had finished publishing. On rare occasions we'd end up with two scripts trying to process the same content.
One of the early design decisions was to use SHA1 hashes to compare content when updating. As you'll see later it made the script more flexible as we fine-tuned the publishing process. Initially the iNews exporter generated SHA1s based on the headline and bodycopy and these were stored in the spare fields in the Matrix news asset. These values could be checked to determine if content had changed.
The second task was to update the iNews exporter to generate the new XML. This proved to be a small challenge as I wanted to run the old and the new import jobs on the same content at the same time. Live content generated by real users is the best test data you can get, so new attributes were added to the XML where required to support this.
The first 3 weeks of testing were used to streamline the export script and write unit tests for the import script. I also added code to the exporter to process updates and removals of stories.
Add. This mode is simple enough - if the story was not in the system, add it.
Update. The update function used the headline of story to determine a match with an existing story on the site. We limited the match to content in the last 24 hours.
This created a problem though - if the headline was changed the system would not be able to find the original. To get around this I created the 'replace' mode. To replace a headline staff would go to the site and locate the story they wanted, capture the last segment of the URL, and paste this into the story with a special code.
In practice this proved to be unwieldy and was unworkable. It completely interrupted the flow of news processing, and we dropped it after only 24 hours of testing.
As an aside, the purpose of a long test period is to solve not only technical issues, but also operational ones. The technology should facilitate a simple work-flow that allows staff to get on with their work. The technical side of things should be as transparent as possible; it is the servant, not the master.
What was needed was a unique ID that stayed with a story for its life in the system. iNews does assign a unique ID to every story, but these are lost when the content is duplicated in the system or published. After looking at the system again, I discovered (and I am kicking myself for not noticing earlier) that the creator id and timestamp are unique for every story, and are retained even when copies are made.
It was simple matter to derive a SHA1 from this data, instead of the headline, and use that for matching stories in the import script. Had I not used a spare field in the CMS to hold the SHA1, we'd have had to rework the code.
After a couple of days testing using the new SHA1, it worked perfectly - staff could update the headline or bodycopy of any story in iNews and when published it would update on the test page without any extra work.
This updated process allowed staff to have complete control over the listing order and content of stories simply by publishing them as a group. If only the story order was altered, the updated time on the story was not changed.
It has worked out to be very simple, but effective.
Kill. To kill a story a special code is entered into the body of the story. The import script sets the mode to kill and the CMS importer purges it from the system.
Because of the all the work done on the iNews export script, I decided to fix the issues mentioned above - partial publishes, 1 minute cycle time, and two scripts working at once.
The new script checks for content every 3 seconds, waits for iNews to finish publishing, and uses locking to avoid multiple jobs clashing. I'll cover the gory details of the script in a later post.
And work continues to make the publishing process even simpler - I am looking at ways to remotely move content between categories and to simplify the process to kill items.
We use the MySource Matrix CMS, and categorising content is a trivial exercise using the built in asset listing pages. The tricky part in our case is that none of our news staff actually write their content directly in the CMS, or even have logins. Why?
When we first started using Matrix, the system's functionality was much more limited than it is today (in version 3.18.3). For example, paint layouts - which are used to style news items - had not yet been added to the system.
The available features were perfectly suitable for the service that we were able to offer at that time though.
The tool used by our journalists is iNews - a system optimised for processing news content in a large news environment - and it was significantly faster than Matrix for this type of work (as it should be). Because staff were already adept at using it, we decided to use iNews to edit and compile stories and export the result to the CMS.
This would also mean that staff didn't have to know any HTML, and we could add simple codes to the text to allow headings and other basic web formatting. It would also dramatically simplify initial and on-going training.
The proposed process required two scripts. The first script captured the individual iNews stories, ordered them, converted the content to HTML, and packaged them with some metadata into an XML file. (iNews can output a group to stories via ftp with a single command).
The XML was copied to the CMS server where script 2 imported the specified content.

Each block of stories was placed in a folder in the CMS. The most recent folder represented the current publish, and was stamped with the date and time. The import script then changed the settings on the site's home page headline area, the RSS news feed and the News home to list the stories in this new folder.
Stories appeared on the site as they were ordered in the iNews system, and the first five were automatically displayed on the home page.
On the site, story URLs looked like this:
www.radionz.co.nz/news/200807221513/134e5321
and each new publish replaced the any previous versions:
www.radionz.co.nz/news/200807221545/2ed5432
On the technical side, the iNews processing script ran once a minute via a cron job, but over time we found two problems with this approach.
The first was that the URL for a story was not unique over time - each update got a new URL. RSS readers had trouble working our what was new content and not just a new publish of the same story. People linking to a story would get a stale version of the content, depending on when it was actually updated.
The second related to the 1 minute cycle time of the processing script. Most of the time this worked fine, but occasionally we'd get a partial publish when the script started before iNews had finished publishing. On rare occasions we'd end up with two scripts trying to process the same content.
The Update
The first thing we had to do was revise the script for importing content. This work was done by Mark Brydon, one of the developers at Squiz. The resulting script allowed us to:- add a new story at a specific location in Matrix.
- update the content in a existing story (keeping the URL).
- remove a story
- put stories into a folder structure based on the the date.
One of the early design decisions was to use SHA1 hashes to compare content when updating. As you'll see later it made the script more flexible as we fine-tuned the publishing process. Initially the iNews exporter generated SHA1s based on the headline and bodycopy and these were stored in the spare fields in the Matrix news asset. These values could be checked to determine if content had changed.
The second task was to update the iNews exporter to generate the new XML. This proved to be a small challenge as I wanted to run the old and the new import jobs on the same content at the same time. Live content generated by real users is the best test data you can get, so new attributes were added to the XML where required to support this.
The first 3 weeks of testing were used to streamline the export script and write unit tests for the import script. I also added code to the exporter to process updates and removals of stories.
Add. This mode is simple enough - if the story was not in the system, add it.
Update. The update function used the headline of story to determine a match with an existing story on the site. We limited the match to content in the last 24 hours.
This created a problem though - if the headline was changed the system would not be able to find the original. To get around this I created the 'replace' mode. To replace a headline staff would go to the site and locate the story they wanted, capture the last segment of the URL, and paste this into the story with a special code.
In practice this proved to be unwieldy and was unworkable. It completely interrupted the flow of news processing, and we dropped it after only 24 hours of testing.
As an aside, the purpose of a long test period is to solve not only technical issues, but also operational ones. The technology should facilitate a simple work-flow that allows staff to get on with their work. The technical side of things should be as transparent as possible; it is the servant, not the master.
What was needed was a unique ID that stayed with a story for its life in the system. iNews does assign a unique ID to every story, but these are lost when the content is duplicated in the system or published. After looking at the system again, I discovered (and I am kicking myself for not noticing earlier) that the creator id and timestamp are unique for every story, and are retained even when copies are made.
It was simple matter to derive a SHA1 from this data, instead of the headline, and use that for matching stories in the import script. Had I not used a spare field in the CMS to hold the SHA1, we'd have had to rework the code.
After a couple of days testing using the new SHA1, it worked perfectly - staff could update the headline or bodycopy of any story in iNews and when published it would update on the test page without any extra work.
This updated process allowed staff to have complete control over the listing order and content of stories simply by publishing them as a group. If only the story order was altered, the updated time on the story was not changed.
It has worked out to be very simple, but effective.
Kill. To kill a story a special code is entered into the body of the story. The import script sets the mode to kill and the CMS importer purges it from the system.
Because of the all the work done on the iNews export script, I decided to fix the issues mentioned above - partial publishes, 1 minute cycle time, and two scripts working at once.
The new script checks for content every 3 seconds, waits for iNews to finish publishing, and uses locking to avoid multiple jobs clashing. I'll cover the gory details of the script in a later post.
Summary
The new scripts and work processes are now being used for live content. Each story gets a category code plus an optional code to put it in the top 5 on the home page. The story order in iNews is reflected on the site, and it is possible to correct old stories. It's all very simple to use and operate, and doesn't get in the way of publishing news.And work continues to make the publishing process even simpler - I am looking at ways to remotely move content between categories and to simplify the process to kill items.
Monday, July 21, 2008
Te Wiki o te Reo Māori - Māori Language Week
I made a few changes to the Radio NZ site this morning as part of the company's initiative for Māori Language Week.
The most obvious is the change in font size on the te Reo versions of headings.
This was achieved across the whole site by changing one line and adding a second to our master CSS file.
From this:
to this:
We've also extended the bi-lingual headings beyond the home page to other parts of the site.
The second change is the substitution of te Reo for English in the left side menu on all pages. Hovering over the headings on most modern browsers displays a tool tip with the English equivalent.
If you look at the code on any page (I could not get blogger to display it), there is a span with the class hide. This is for users of screen-readers, and ensures that the verbal rendering of the headings remained consistent with other headings on the site.
The other major addition is some bi-lingual pages. The about us page is an example.
There are links at the top of the page that allow visitors to select which language they want, or to see both side-by-side.
The page is laid out with a series of alternating divs - one for each language - and they are styled with CSS to sit alongside each other.
The links use Javascript to show and hide the sections.
To return the original design at the end of the week it'll be a simple matter to restore the CSS, and swap a few bits of text in the master site template.
The most obvious is the change in font size on the te Reo versions of headings.
This was achieved across the whole site by changing one line and adding a second to our master CSS file.
From this:
h2.bi .reo{font-size:12px; padding: 0; text-transform:none;}to this:
h2.bi .eng{font-size:12px; padding: 0; text-transform:none;}
h2.bi .reo{font-size:19px; padding: 0; text-transform:none;}We've also extended the bi-lingual headings beyond the home page to other parts of the site.
The second change is the substitution of te Reo for English in the left side menu on all pages. Hovering over the headings on most modern browsers displays a tool tip with the English equivalent.
If you look at the code on any page (I could not get blogger to display it), there is a span with the class hide. This is for users of screen-readers, and ensures that the verbal rendering of the headings remained consistent with other headings on the site.
The other major addition is some bi-lingual pages. The about us page is an example.
There are links at the top of the page that allow visitors to select which language they want, or to see both side-by-side.
The page is laid out with a series of alternating divs - one for each language - and they are styled with CSS to sit alongside each other.
The links use Javascript to show and hide the sections.
To return the original design at the end of the week it'll be a simple matter to restore the CSS, and swap a few bits of text in the master site template.
Wednesday, July 16, 2008
Some interesting statistics
I have just read the news about Firefox download day, so I thought I'd go and look Radio NZ's web stats to see what happened to Firefox 3 usage.

Yep, looks like a lot of people started using FF3, but were they upgrades, or new users? This is the graph of the total number of FF users over the same period.

There is no statistically relevant change.
I've noticed that FF users quickly upgrade compared with IE users. Of version 2 users, 98% of them are on the latest release - 2.0.0.14 at the time of writing (end of June). Less than 2 % of all FF users are still on version 1.
Looking at IE use in June 2008 we can see the position two years after IE7 was launched:
IE 7: 62.1 %
IE6: 37.4 %
IE5.5: 0.26 %
IE5.0: 0.13 %
The changes in browser use over time are also interesting.
IE use is down and everything else is up.
I thought I'd look at operating systems use over the same period:
I'm also seeing in increase in platforms like PlayStation, iPhone (starting before the release of the 3g in NZ), Symbian, and even Nintendo Wii.
From a Webmaster's point of view, these changes suggest that my approach to content is going to have to become more platform agnostic as time passes.
Yep, looks like a lot of people started using FF3, but were they upgrades, or new users? This is the graph of the total number of FF users over the same period.
There is no statistically relevant change.
I've noticed that FF users quickly upgrade compared with IE users. Of version 2 users, 98% of them are on the latest release - 2.0.0.14 at the time of writing (end of June). Less than 2 % of all FF users are still on version 1.
Looking at IE use in June 2008 we can see the position two years after IE7 was launched:
IE 7: 62.1 %
IE6: 37.4 %
IE5.5: 0.26 %
IE5.0: 0.13 %
The changes in browser use over time are also interesting.
| Browser | Oct '06 | Aug '07 | Jun '08 |
|---|---|---|---|
| IE | 73.46 | 69.15 | 65.61 |
| FF | 19.53 | 23.45 | 26.99 |
| Safari | 4.69 | 5.03 | 5.44 |
| Opera | 0.82 | 0.86 | 1.09 |
IE use is down and everything else is up.
I thought I'd look at operating systems use over the same period:
| OS | Oct '06 | Aug '07 | Jun '08 |
|---|---|---|---|
| Windows | 92.69 | 91.37 | 90.51 |
| OS X | 6.32 | 7.40 | 8.02 |
| Linux | 0.83 | 1.01 | 1.26 |
I'm also seeing in increase in platforms like PlayStation, iPhone (starting before the release of the 3g in NZ), Symbian, and even Nintendo Wii.
From a Webmaster's point of view, these changes suggest that my approach to content is going to have to become more platform agnostic as time passes.
Tuesday, July 15, 2008
Dated URLs for Radio NZ audio
At the moment on the Radio NZ site all the audio for a programme appears in the following format:
This is reflected in our CMS with audio appearing in one folder. Due to the number of audio items we now have in each folder (and growing each day) it is getting difficult to manage.
Starting today, we are migrating to a date-based system for audio URLs. They'll follow this format:
Some programmes may only have a year or year/month structure, depending on how often it is broadcast.
This is being done programme by programme and may take a month or two to complete, as we have to change the pages that list the audio as well.
The first programme to use this format is Saturday Morning with Kim Hill.
One challenge in the process was the task of moving assets from the old structure to the new.
A Squiz developer has written a script that does the job for us.
This command moves all the audio items under asset number 26411 into year/month/day folders based on the date the asset was created. At the moment the created folders are under construction, but I have asked for a parameter so they can be made live instead.
We need to do this now before we extend the time-frame audio is available to the public (1 - 4 weeks at present). It won't be possible to move the content later on without breaking links.
www.radionz.co.nz/audio/progamme/tracknameThis is reflected in our CMS with audio appearing in one folder. Due to the number of audio items we now have in each folder (and growing each day) it is getting difficult to manage.
Starting today, we are migrating to a date-based system for audio URLs. They'll follow this format:
www.radionz.co.nz/audio/programme/year/month/day/tracknameSome programmes may only have a year or year/month structure, depending on how often it is broadcast.
This is being done programme by programme and may take a month or two to complete, as we have to change the pages that list the audio as well.
The first programme to use this format is Saturday Morning with Kim Hill.
One challenge in the process was the task of moving assets from the old structure to the new.
A Squiz developer has written a script that does the job for us.
move_assets_to_dated_folders.php /path/to/radionz 26411 audio_item created dayThis command moves all the audio items under asset number 26411 into year/month/day folders based on the date the asset was created. At the moment the created folders are under construction, but I have asked for a parameter so they can be made live instead.
We need to do this now before we extend the time-frame audio is available to the public (1 - 4 weeks at present). It won't be possible to move the content later on without breaking links.
Sunday, July 6, 2008
Equal Height Columns with MooTools
There are a number of Javascript solutions around for creating equal height columns in a design. They all work in pretty much the same way - you generally specify the required columns in the height function, and run it after the DOM is available.
On the Radio NZ site I recently ported our old column function to use the Mootools library.
Here is the old function:
The second loop finds the tallest div, and the last loop changes the height of each div to that value (taking into account any CSS padding).
The Mootools version is much simpler:
On the Radio NZ site I recently ported our old column function to use the Mootools library.
Here is the old function:
/* SetTall by Paul@YellowPencil.com and Scott@YellowPencil.com */
function setTall() {
if (document.getElementById) {
var divs = Array();
var list = new Array('cont-pri','cont-sec','hleft','hright','features','snw');
count = 0;
for (var i = 0; i < list.length; i++) {
if ( (temp = document.getElementById(list[i]) ) ){
divs[count] = temp;
count++;
}
}
var mH = 0;
for (var i = 0; i < divs.length; i++) {
if (divs[i].offsetHeight > mH) mH = divs[i].offsetHeight;
}
for (var i = 0; i < divs.length; i++) {
divs[i].style.height = mH + 'px';
if (divs[i].offsetHeight > mH) {
divs[i].style.height = (mH - (divs[i].offsetHeight - mH)) + 'px';
}
}
}
}
The second loop finds the tallest div, and the last loop changes the height of each div to that value (taking into account any CSS padding).
The Mootools version is much simpler:
function equalHeights() {
var height = 0;
divs = $$('#cont-pri','#cont-sec','#hleft','#hright','#features','#snw');
divs.each( function(e){
if (e.offsetHeight > height){
height = e.offsetHeight;
}
});
divs.each( function(e){
e.setStyle( 'height', height + 'px' );
if (e.offsetHeight > height) {
e.setStyle( 'height', (height - (e.offsetHeight - height)) + 'px' );
}
});
}
The first call to $$ returns only valid divs, eliminating the need to check. The each iterator is then used twice - the first time to get the maximum height, and the second to set all the divs to that height.
Wednesday, July 2, 2008
Loading Content on Demand with Mootools
In my last post I explained some changes I've made to the Radio New Zealand website to improve page rendering times and reduce bandwidth.
In this post I'll explain another change that loads some page content on-demand with an AJAX call, saving even more bandwidth.
One of the fun features of the site is that the content layout changes slightly depending on the width of the browser port. When the browser is less than 800px wide the listener image in the header reduces in size, and the menu moves to the left. When it expands beyond 1200px an extra content column is added to the layout. At the moment this extra column duplicates the features content from the home page, but in the future we could customise it for each section of the site.
The content is shown (or hidden) by dynamically changing the available CSS rules for the page, based on the viewport size.
There is one disadvantage to this approach though - all the required content has to be served for every page request, regardless of whether the end user ever sees it. Based on site stats, the cost of this is non-trivial.
According to Google Analytics:
As from today, no more. If you care to look at the source code for this page with your browser set to 1024 wide you'll see an empty div with id = features.
When the page width extends beyond 1200 px, a javascript call is made to fetch the div's content from the server and insert it into the page.
A simple and effective way to save 8.5 gigabytes of traffic a month. Combined with yesterday's effort that's 30 gigabytes of saving a month.
In this post I'll explain another change that loads some page content on-demand with an AJAX call, saving even more bandwidth.
One of the fun features of the site is that the content layout changes slightly depending on the width of the browser port. When the browser is less than 800px wide the listener image in the header reduces in size, and the menu moves to the left. When it expands beyond 1200px an extra content column is added to the layout. At the moment this extra column duplicates the features content from the home page, but in the future we could customise it for each section of the site.
The content is shown (or hidden) by dynamically changing the available CSS rules for the page, based on the viewport size.
There is one disadvantage to this approach though - all the required content has to be served for every page request, regardless of whether the end user ever sees it. Based on site stats, the cost of this is non-trivial.
According to Google Analytics:
- 44% of RNZ visitors have 1024px as their screen width, with most of the rest being higher.
- We had 700,000 page impressions in June (excluding the home page).
As from today, no more. If you care to look at the source code for this page with your browser set to 1024 wide you'll see an empty div with id = features.
When the page width extends beyond 1200 px, a javascript call is made to fetch the div's content from the server and insert it into the page.
A simple and effective way to save 8.5 gigabytes of traffic a month. Combined with yesterday's effort that's 30 gigabytes of saving a month.
Tuesday, July 1, 2008
Improving page load speeds
When building a site, I try to make pages as small as practicable. The aim is to reduce load times for visitors and so provide a better experience as they move around the site.
There are several reasons for this:
1. There is a correlation between the speed of the site and the perceived credibility of the company and the content.
2. Many New Zealanders are still on dial-up.
3. Bandwidth costs money, which is always scarce (bandwidth is sometimes scarce too).
4. Serving smaller pages puts less load on servers.
I have just made some changes to www.radionz.co.nz to improve page load times and reduce bandwidth.
The first of these changes was to stop using sIFR. Scalable Inman Flash Replacement (to quote the site), "...is meant to replace short passages of plain browser text with text rendered in your typeface of choice, regardless of whether or not your users have that font installed on their systems."
When we launched the new version of the site 18 months ago, sIFR was to render all headings in one of our corporate typefaces. The system worked very well, but required a small flash movie (14kb) and some javascript (28kb). There was also an annoying bump of a few pixels when the flash movie was added to the page - something that I was never able to fully resolve.
The advantage of using sIFR over the traditional method of using images for headings is that if any text is changed, or new pages are added, the text is automatically replaced. We add dozens of new pages every day, so this is a big time-saver.
As the site has grown in size and the number of visitors increased, the 42 kb download and the slower rendering time started to annoy me. Even when content on a page didn't change and was cached in the user's browser, there was still a delay while the headings were replaced.
Lastly, the typeface did not have any macronised vowels, so it was not possible to correctly set headings in Māori.
So last week I removed sIFR from the site. It was a very tough call as the sIFR replaced fonts look really good, and added a certain polish to the site. But with any change you have to weigh all the pros and cons, and at this time the benefits to end-users where overwhelming. (There are also some other changes that I'm making in the near future that'll be simpler without sIFR, but more about that later).
Upon removal, the page rendering improvement was immediately obvious on broadband, and I suspect that on dial-up it will be even more marked.
The other side-effects of this change are slightly reduced server loading (from fewer connections) and a reduction in the amount of bandwidth used by around 800 megabytes per day. (We shift about 8 gigabytes of page traffic a day. The audio is many, many times this figure).
The second phase of the speed improvement was to change the way javascript is loaded. On Monday this week I made two changes.
The first was to use Google's new content delivery network to serve mootools. This javascript library is used for a number of effects on the site such as the accordion in the audio popup (click on the headphones at the top of any page), and all the picture gallery pages.
There are a number of advantages in doing this, summarised nicely by Steve Souders. In a nutshell, the Google servers are optimised to minimise the size of the content, and content headers are set to encourage caching of the content at the ISP and browser. It works even better if other sites use the same library - it increases the likelhood that the content is already cached somewhere, spreading the benefits more widely.
I could have made these changes on our own server, but it doesn't cost anything to support the initiative so why not? I don't know how many other NZ sites use mootools, but a lot of the bigger sites use prototype and they could benefit from better site performance, lower bandwidth use, and improved user experience by adopting this approach.
The second change that I made was to move all our javascript to the bottom of the page. This ensures that the HTML and CSS are loaded first and have a chance to render in the browser. This is one of the recomendations made by the Yahoo performance team for speeding up websites.
The difference in rendering is quite noticeable, and on slower connection you can see the scripts continuing to download after the current page is showing.
In the case of the Radio New Zealand site we've reduced the rendering time for pages by 3 - 4 seconds and trimmed bandwidth consumption by about 10%. The changes took 3 hours to plan, test and implement.
At the rate we consume traffic, the payback period is pretty short. Add to that future savings from not having to replace the servers quite so soon, and the unmeasurable cost of delivering pages faster to visitors (who don't use as much of their data caps) , I'd say it was time well spent.
There are several reasons for this:
1. There is a correlation between the speed of the site and the perceived credibility of the company and the content.
2. Many New Zealanders are still on dial-up.
3. Bandwidth costs money, which is always scarce (bandwidth is sometimes scarce too).
4. Serving smaller pages puts less load on servers.
I have just made some changes to www.radionz.co.nz to improve page load times and reduce bandwidth.
The first of these changes was to stop using sIFR. Scalable Inman Flash Replacement (to quote the site), "...is meant to replace short passages of plain browser text with text rendered in your typeface of choice, regardless of whether or not your users have that font installed on their systems."
When we launched the new version of the site 18 months ago, sIFR was to render all headings in one of our corporate typefaces. The system worked very well, but required a small flash movie (14kb) and some javascript (28kb). There was also an annoying bump of a few pixels when the flash movie was added to the page - something that I was never able to fully resolve.
The advantage of using sIFR over the traditional method of using images for headings is that if any text is changed, or new pages are added, the text is automatically replaced. We add dozens of new pages every day, so this is a big time-saver.
As the site has grown in size and the number of visitors increased, the 42 kb download and the slower rendering time started to annoy me. Even when content on a page didn't change and was cached in the user's browser, there was still a delay while the headings were replaced.
Lastly, the typeface did not have any macronised vowels, so it was not possible to correctly set headings in Māori.
So last week I removed sIFR from the site. It was a very tough call as the sIFR replaced fonts look really good, and added a certain polish to the site. But with any change you have to weigh all the pros and cons, and at this time the benefits to end-users where overwhelming. (There are also some other changes that I'm making in the near future that'll be simpler without sIFR, but more about that later).
Upon removal, the page rendering improvement was immediately obvious on broadband, and I suspect that on dial-up it will be even more marked.
The other side-effects of this change are slightly reduced server loading (from fewer connections) and a reduction in the amount of bandwidth used by around 800 megabytes per day. (We shift about 8 gigabytes of page traffic a day. The audio is many, many times this figure).
The second phase of the speed improvement was to change the way javascript is loaded. On Monday this week I made two changes.
The first was to use Google's new content delivery network to serve mootools. This javascript library is used for a number of effects on the site such as the accordion in the audio popup (click on the headphones at the top of any page), and all the picture gallery pages.
There are a number of advantages in doing this, summarised nicely by Steve Souders. In a nutshell, the Google servers are optimised to minimise the size of the content, and content headers are set to encourage caching of the content at the ISP and browser. It works even better if other sites use the same library - it increases the likelhood that the content is already cached somewhere, spreading the benefits more widely.
I could have made these changes on our own server, but it doesn't cost anything to support the initiative so why not? I don't know how many other NZ sites use mootools, but a lot of the bigger sites use prototype and they could benefit from better site performance, lower bandwidth use, and improved user experience by adopting this approach.
The second change that I made was to move all our javascript to the bottom of the page. This ensures that the HTML and CSS are loaded first and have a chance to render in the browser. This is one of the recomendations made by the Yahoo performance team for speeding up websites.
The difference in rendering is quite noticeable, and on slower connection you can see the scripts continuing to download after the current page is showing.
In the case of the Radio New Zealand site we've reduced the rendering time for pages by 3 - 4 seconds and trimmed bandwidth consumption by about 10%. The changes took 3 hours to plan, test and implement.
At the rate we consume traffic, the payback period is pretty short. Add to that future savings from not having to replace the servers quite so soon, and the unmeasurable cost of delivering pages faster to visitors (who don't use as much of their data caps) , I'd say it was time well spent.
Monday, June 23, 2008
Managing code customisations with Git (Part Two)
In my first post I showed how I use Git rebase to integrate upstream code changes into projects.
In this second post I'll show a simple way to manage client code branches. (Well, simple compared with CVS and SVN).
In this example, I imagine that each client has their own custom changes to the core code base, and also packages that live in a client directory in their own part of the code tree.
I'll be assuming that you already have a repository to work with. In this case I have committed all the public releases of MySource Matrix (the CMS I use at work) to Git, creating a new branch for each public release.
We start at the prompt:
The current working copy is at the head of the master branch, which in this case contains release 3.18.2. The current branch name is shown in my prompt.
First, I'm going to change to the 3.16 branch of the repo and create a client branch. In Git this is done with the checkout command.
We are now at the head of the 3.16 branch. The last version on this branch (in my case) is 3.16.8.
I'll create a client branch.
In the real world this would be a development repository, so there would be a lot of other commits and you'd likely base your branch off a release tag, rather than the head.
To keep things simple I am going to make two changes - one to an existing file, and add one new file.
The first alteration is to the CHANGELOG. I'll add some text after the title.
After making the change, we can see the status of Git:
You can also see the changes with diff.
So I'll commit this change:
(I'm ignoring the other change to the file - an extended character replacement that my editor seems to have done for me).
Now I'll add a file outside the core - one in our own package. Looking at git status:
We need to add this file to Git as it is not currently tracked:
And then commit it.
Looking at gitk you can see that the client branch is now two commits ahead of the 3.16 branch.
We'll assume that this client code is now in production, and a new version of Matrix is released.
In order to move the 3.16 branch forward for this example, I'll add the latest release. First I'll checkout the code branch that we based our client branch on:
If you check in the working directory you'll see that any changes have gone. The working directory now reflects the state of the head of the new branch.
I'll extract the new code release over the top of the current working copy.
If we look at git status we can see some files changed and some files added.
Then add all changes and new files to the index ready to commit:
I'll then commit them:
Let's look at gitk again:
You can see that the 3.16 branch and the client branch have split - they both have changes that the other branch doesn't. (In practice this would be a series of commits and a release tag, although people using the GPL version could manage their local codebase exactly as I describe it here).
There are two ways to go at this point, rebase and merge.
Rebase allows us to reapply our branch changes on top of the 3.16 branch, effectively retaining our custom code. (The package code is not a problem as it only exists in our client branch.)
Rebase checks the code you are coming from and the code you are going to. If there is a conflict with any code you have changed on the branch, then you'll be warned that there is a clash to resolve.
Let's do the rebase:
I'll walk though each step of the process:
This is telling git to rebase the current branch on top of the head of the v3.16 branch.
git is changing the working copy (this is a checkout, and it shows the commit message).
The next block is git re-applying the first commit you made on your client branch on top of the the checkout.
In this case git found the line we changed in the core and was able to auto-merge the change.
This last line was the second commit. As this contained new files not in the core, the patch was trivial.
This is what the rebase looks like:
You can see that the branch appears to have been removed from the original branch point (release 3.16.8) and reconnected later (release 3.16.9).
The following merges the current state of the 3.16 branch (release 3.16.9) into the client branch.
All new files are pulled in, and any other changes are applied to existing files. Custom changes are retained, and conflicts are marked. This is what the merge looks like:
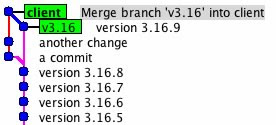
At this point you can retain the client branch and merge from 3.16.10 when it arrives (or indeed from 3.18 if you want).
If thing go wrong (there is a conflict) you'll get the change to resolve the conflict. Git will give a range of options. You'll need to resolve any conflicts.
A conflict will occur when the current branch and the merge target have the different changes on the same line (or lines). This can be manually resolved, and this ensures that your custom changes are retained (or updated).
Just released in git 1.5.6 is the ability to list branches that have been merged (and not merged) to the current branch. This would be useful to see what code has ended up in a client branch.
I'd suggest you view the gitcasts for rebase and merging, as these show how to resolve conflicts and some other advanced topics.
2. The repository I have shown here is somewhat subversion-esque in that there is a trunk and release branches. It would be just as simple to have the master branch being stable and containing tagged releases, with all the development and bug fixes being done on other branches. (Bugs fixes and development work are merged back into the stable release [master] branch). This is how many git repositories are set up, and this also is the way I tend to use it for new projects.
3. Because branching (and merging) is so simple in Git, I use it all the time. You can do all sort of useful things. For example, you could branch off a client branch, add some special feature, and then merged this back into any other branch - another client, release, or development. You could base a feature of a particular tag, merge it into two client branches, update it for PHP5, update the client branch packages for PHP5, merge in the feature and then merge in the upstream PHP5 changes.
SVN users have probably passed-out at this point.
Have fun.
In this second post I'll show a simple way to manage client code branches. (Well, simple compared with CVS and SVN).
In this example, I imagine that each client has their own custom changes to the core code base, and also packages that live in a client directory in their own part of the code tree.
I'll be assuming that you already have a repository to work with. In this case I have committed all the public releases of MySource Matrix (the CMS I use at work) to Git, creating a new branch for each public release.

We start at the prompt:
qed:~/mysource_matrix [master] $The current working copy is at the head of the master branch, which in this case contains release 3.18.2. The current branch name is shown in my prompt.
First, I'm going to change to the 3.16 branch of the repo and create a client branch. In Git this is done with the checkout command.
qed:~/mysource_matrix [master] $ git checkout v3.16
Checking out files: 100% (2426/2426), done.
Switched to branch "v3.16"
qed:~/mysource_matrix [v3.16] $We are now at the head of the 3.16 branch. The last version on this branch (in my case) is 3.16.8.
I'll create a client branch.
qed:~/mysource_matrix [v3.16] $ git checkout -b client
Switched to a new branch "client"
qed:~/mysource_matrix [client] $In the real world this would be a development repository, so there would be a lot of other commits and you'd likely base your branch off a release tag, rather than the head.
To keep things simple I am going to make two changes - one to an existing file, and add one new file.
The first alteration is to the CHANGELOG. I'll add some text after the title.
After making the change, we can see the status of Git:
qed:~/mysource_matrix [client] $ git status
# On branch client
# Changed but not updated:
# (use "git add ..." to update what will be committed)
#
# modified: CHANGELOG
#
no changes added to commit (use "git add" and/or "git commit -a") You can also see the changes with diff.
qed:~/mysource_matrix [client] $ git diff
diff --git a/CHANGELOG b/CHANGELOG
index a1240cb..54f5f50 100755
--- a/CHANGELOG
+++ b/CHANGELOG
@@ -1,4 +1,4 @@
-MYSOURCE MATRIX CHANGELOG
+MYSOURCE MATRIX CHANGELOG (Client Version)
VERSION 3.16.8
So I'll commit this change:
qed:~/mysource_matrix [client] $ git commit -a -m"changed title code in core"
Created commit 54a3c24: changed title code in core
1 files changed, 2 insertions(+), 2 deletions(-)(I'm ignoring the other change to the file - an extended character replacement that my editor seems to have done for me).
Now I'll add a file outside the core - one in our own package. Looking at git status:
qed:~/mysource_matrix [client] $ git status
# On branch client
# Untracked files:
# (use "git add ..." to include in what will be committed)
#
# packages/client/
nothing added to commit but untracked files present (use "git add" to track) We need to add this file to Git as it is not currently tracked:
qed:~/Downloads/mysource_matrix [client] $ git add packages/client/client_code.incAnd then commit it.
qed:~/mysource_matrix [client] $ git commit -m"added client package"
Created commit 82ac0ed: added client package
1 files changed, 5 insertions(+), 0 deletions(-)
create mode 100644 packages/client/client_code.incLooking at gitk you can see that the client branch is now two commits ahead of the 3.16 branch.

We'll assume that this client code is now in production, and a new version of Matrix is released.
In order to move the 3.16 branch forward for this example, I'll add the latest release. First I'll checkout the code branch that we based our client branch on:
qed:~/mysource_matrix [client] $ gco v3.16
Switched to branch "v3.16"If you check in the working directory you'll see that any changes have gone. The working directory now reflects the state of the head of the new branch.
I'll extract the new code release over the top of the current working copy.
qed:~/$ tar xvf mysource_3-16-9.tar.gzIf we look at git status we can see some files changed and some files added.
qed:~/mysource_matrix [v3.16] $ git status
# On branch v3.16
# Changed but not updated:
# (use "git add ..." to update what will be committed)
#
# modified: CHANGELOG
# modified: core/assets/bodycopy/bodycopy_container/bodycopy_container.inc
# modified: core/assets/designs/design_area/design_area_edit_fns.inc
# SNIP: Full file list removed for brevity
# modified: scripts/add_remove_url.php
#
# Untracked files:
# (use "git add ..." to include in what will be committed)
#
# packages/cms/hipo_jobs/
# packages/cms/tools/
no changes added to commit (use "git add" and/or "git commit -a") Then add all changes and new files to the index ready to commit:
qed:~/mysource_matrix [v3.16] $ git add .I'll then commit them:
qed:~/Downloads/mysource_matrix [v3.16] $ git commit -m"v3.16.9"
Created commit ea7a183: v3.16.9
33 files changed, 1412 insertions(+), 110 deletions(-)
create mode 100755 packages/cms/hipo_jobs/hipo_job_tool_export_files.inc
create mode 100755 packages/cms/tools/tool_export_files/asset.xml
create mode 100755 packages/cms/tools/tool_export_files/tool_export_files.inc
create mode 100755 packages/cms/tools/tool_export_files/tool_export_files_edit_fns.inc
create mode 100755 packages/cms/tools/tool_export_files/tool_export_files_management.incLet's look at gitk again:

You can see that the 3.16 branch and the client branch have split - they both have changes that the other branch doesn't. (In practice this would be a series of commits and a release tag, although people using the GPL version could manage their local codebase exactly as I describe it here).
There are two ways to go at this point, rebase and merge.
Rebase
This can be used in a single local repository.Rebase allows us to reapply our branch changes on top of the 3.16 branch, effectively retaining our custom code. (The package code is not a problem as it only exists in our client branch.)
Rebase checks the code you are coming from and the code you are going to. If there is a conflict with any code you have changed on the branch, then you'll be warned that there is a clash to resolve.
Let's do the rebase:
qed:~/mysource_matrix [client] $ git rebase v3.16
First, rewinding head to replay your work on top of it...
HEAD is now at b67fef6 version 3.16.9
Applying changed title code in core
error: patch failed: CHANGELOG:1
error: CHANGELOG: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
Auto-merged CHANGELOG
Applying added client package
I'll walk though each step of the process:
qed:~/mysource_matrix [client] $ git rebase v3.16This is telling git to rebase the current branch on top of the head of the v3.16 branch.
First, rewinding head to replay your work on top of it...
HEAD is now at b67fef6 version 3.16.9git is changing the working copy (this is a checkout, and it shows the commit message).
Applying changed title code in core
error: patch failed: CHANGELOG:1
error: CHANGELOG: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
Auto-merged CHANGELOGThe next block is git re-applying the first commit you made on your client branch on top of the the checkout.
In this case git found the line we changed in the core and was able to auto-merge the change.
Applying added client packageThis last line was the second commit. As this contained new files not in the core, the patch was trivial.
This is what the rebase looks like:

You can see that the branch appears to have been removed from the original branch point (release 3.16.8) and reconnected later (release 3.16.9).
Merge
Merge is the best option when you want to make the client branches and their histories available to other people. This would happen when there are multiple developers working in the same code.The following merges the current state of the 3.16 branch (release 3.16.9) into the client branch.
qed:~/mysource_matrix [client] $ git merge v3.16
Auto-merged CHANGELOG
Merge made by recursive.
CHANGELOG | 126 +++++
.../bodycopy_container/bodycopy_container.inc | 11 +-
.../designs/design_area/design_area_edit_fns.inc | 6 +-
SNIP: a bunch of file changes and additions
create mode 100755 scripts/regen_metadata_schemas.phpAll new files are pulled in, and any other changes are applied to existing files. Custom changes are retained, and conflicts are marked. This is what the merge looks like:

At this point you can retain the client branch and merge from 3.16.10 when it arrives (or indeed from 3.18 if you want).
If thing go wrong (there is a conflict) you'll get the change to resolve the conflict. Git will give a range of options. You'll need to resolve any conflicts.
A conflict will occur when the current branch and the merge target have the different changes on the same line (or lines). This can be manually resolved, and this ensures that your custom changes are retained (or updated).
Just released in git 1.5.6 is the ability to list branches that have been merged (and not merged) to the current branch. This would be useful to see what code has ended up in a client branch.
I'd suggest you view the gitcasts for rebase and merging, as these show how to resolve conflicts and some other advanced topics.
A few other points
1. You should not publish branches that have been rebased. The manpage is clear:"When you rebase a branch, you are changing its history in a way that will cause problems for anyone who already has a copy of the branch in their repository and tries to pull updates from you. You should understand the implications of using git rebase on a repository that you share."This might be a problem if many developers are sharing code from a 'master' git repository, and more than one need access to these branches. Better to use merge in these cases.
2. The repository I have shown here is somewhat subversion-esque in that there is a trunk and release branches. It would be just as simple to have the master branch being stable and containing tagged releases, with all the development and bug fixes being done on other branches. (Bugs fixes and development work are merged back into the stable release [master] branch). This is how many git repositories are set up, and this also is the way I tend to use it for new projects.
3. Because branching (and merging) is so simple in Git, I use it all the time. You can do all sort of useful things. For example, you could branch off a client branch, add some special feature, and then merged this back into any other branch - another client, release, or development. You could base a feature of a particular tag, merge it into two client branches, update it for PHP5, update the client branch packages for PHP5, merge in the feature and then merge in the upstream PHP5 changes.
SVN users have probably passed-out at this point.
Have fun.
Saturday, June 21, 2008
Managing Code customisations with Git (Part One)
After using Git for a couple of months on projects of my own, I learnt how to use rebase to move a branch from one commit to another in the repository.
There are two scenarios where this is useful.
The first is when you deploy code from an open source project, and then make custom changes to that code. You then want to pick up bug fixes and features from an upstream release.
The second is managing client code branches (which I'll talk about in part two).
Shocking as it seems to me now, in the 'old days' I used to keep a changelog which listed all the changes that had been to made to code. Embarrassing.
Here is what I do know, in my day job.
We use MediaWiki internally, but have carried out a number of customisations and patches to add features that are not in the standard release. Some of these are extensions, but a few require changes to the core code.
Managing this in Git has made the task a whole lot simpler than it used to be.
Firstly I created a repository of the standard release by untaring the code, cding into the directory and running:
The second step was to create a branch for our customisations.
I then installed the wiki and committed the changes in our new branch. For testing I have a local copy of the repository where testing is done, and changes are backed up in the master repo.
When a new release of the MediaWiki software is out, I change back to the master branch (on the staging server):
and then untar the new code over the top of the old.
After committing, it is the a simple matter to checkout our branch:
and rebase this off the master.
The rebase command first checks out the working copy of the code from the head of the specified branch, and then reapplies the commits we made on our branch.
I then test, backup the repo, and deploy the changes.
Done!
This strategy is perfect when you have a single repository (although not THAT likely if you are using Git). In the next part I'll show how to manage client code using both rebase and merge.
There are two scenarios where this is useful.
The first is when you deploy code from an open source project, and then make custom changes to that code. You then want to pick up bug fixes and features from an upstream release.
The second is managing client code branches (which I'll talk about in part two).
Shocking as it seems to me now, in the 'old days' I used to keep a changelog which listed all the changes that had been to made to code. Embarrassing.
Here is what I do know, in my day job.
We use MediaWiki internally, but have carried out a number of customisations and patches to add features that are not in the standard release. Some of these are extensions, but a few require changes to the core code.
Managing this in Git has made the task a whole lot simpler than it used to be.
Firstly I created a repository of the standard release by untaring the code, cding into the directory and running:
qed ~/wiki $ git add .
qed ~/wiki $ git commit -m"The initial commit"The second step was to create a branch for our customisations.
qed ~/wiki $ git checkout -b radiowikiI then installed the wiki and committed the changes in our new branch. For testing I have a local copy of the repository where testing is done, and changes are backed up in the master repo.
When a new release of the MediaWiki software is out, I change back to the master branch (on the staging server):
qed ~/wiki $ git checkout masterand then untar the new code over the top of the old.
After committing, it is the a simple matter to checkout our branch:
qed ~/wiki $ git checkout radiowikiand rebase this off the master.
qed ~/wiki $ git rebase masterThe rebase command first checks out the working copy of the code from the head of the specified branch, and then reapplies the commits we made on our branch.
I then test, backup the repo, and deploy the changes.
Done!
This strategy is perfect when you have a single repository (although not THAT likely if you are using Git). In the next part I'll show how to manage client code using both rebase and merge.
Tuesday, June 17, 2008
And now the news...
 One of the challenges with publishing news onto the Radio NZ site was getting the content from our internal news text system into our Content Management System.
One of the challenges with publishing news onto the Radio NZ site was getting the content from our internal news text system into our Content Management System.The newsroom uses iNews to prepare all their copy. The website uses MySource Matrix, a CMS used by many Australian organisations and now starting to get some traction in New Zealand since the local office opened.
There were three options:
- Use iNews to generate the site.
- Get staff to use the CMS directly.
- Wire the two systems together in some way.
The second was considered, but deemed too hard because of the need to create a large custom editing and management area in the CMS. We did not have the resources to build, maintain and support this, along with the required staff training.
The last option was to write some software to allow iNews to publish directly to the CMS.
How it Works
iNews is able to output stories in a specified order via ftp. Staff compile the stories for each publish and press one key to send the content for processing. The stories end up on an internal server in HTML format, with an extra file noting the original order.Processing HTML is always a challenge - the code generated by iNews was not always well-formed - although I already had some software that worked courtesy of Radio NZ International. They'd been publishing content from iNews to their site since 2002, and the script's run there with no issues for 5 years.
The script is 750 lines of Perl code, and runs via a cron job. It reads the order file and processes each HTML file. Files are parsed for metadata such as the published time, and the story content is turned into valid pre-formatted HTML. This is wrapped in XML and pushed to the CMS server.
One of the major advantages of this approach is that staff do not have to learn any HTML, and the system generated HTML can be relied on to meet our site style guidelines. We have defined some formatting codes for use in iNews for basic web formatting:
- [h] Heading
- [s] Summary
- [b] Bold paragraph
- [[text]] Italicize
The script will still add a summary if there is none, as the main news page needs one for every item.
The CMS has an import script that takes the XML data and creates news items on the site. This is activated via a local network connection to our master servers.
I am currently working on an enhanced version of the script that'll allow stories to be categorised and some other cool stuff. More on this in a later post.
Saturday, June 14, 2008
Friday, June 13, 2008
Improving your CSS
The current version of the Radio NZ website was launched in February 2007. A number of people have asked me about the CSS for site, and particularly about the size (only 24k, uncompressed). The previous version of the site had about 85k of CSS.
We use gzip compression on the site, so the served filesize is only 6k, but there are other techniques I used to get the initial file size down.
It could be argued that such optimisations are pointless, because any improvements are swamped by the amount of time it takes for the content to traverse the internet. Some prefer maintainability and readability over optimisation. This is true to a point, but only on broadband. We still have a lot of dial-up in New Zealand, and in these cases the speed of the connection is the bottleneck, not the time taken to travel over the net.
The other issues are performance and cost. If you reduce the size and count of files your servers will be able to deliver more requests. If your traffic is metered then any reduction in size saves money. If you are unconvinced read the interview with Mike Davidson regarding the ESPN relaunch.
My aim is to get the HTML and CSS to the browser as fast as possible so that something can be displayed to the user. The load times on pages has a direct effect on the user's perception of quality.
Here are some of the techniques:
1. Using one file.
This reduces the number of server requests (which speeds things up) and ensures that the browser gets everything it needs at once.
2. Reduce white-space.
All rules in our css file are one line each, and there is minimal other white-space. Even though compression will reduce strings of white-space down to one character, stripping this out first ensures that the compression runs faster (fewer characters to process) and that redundant white-space does not have to be decompressed on the browser side. Prior to moving to a Mac I used to use TopSyle Pro which has some tools to convert a more readable version into something smaller, simply by optimsing white-space and some rules. I took a couple of CSS files from major NZ sites and ran them through cleancss to see what sort of savings could be made.
The first site serves a total of 400k on the home page of which 108k is CSS. This could be reduced by 25k with simple optimisations.
The second site serves a total of 507k on the home page of which 56k is CSS. This could be reduced by 28% for a 14k saving.
John at projectx did a more detailed analysis of the top NZ home pages and Government sites using the yslow benchmarks. Interesting reading.
3. Use CSS inheritance
I start all my CSS files this way.
This rule resets all elements to no margin, no padding. (The font-size is required to sort out some rendering issues in Internet Explorer when using ems.)
It is a good place to start styling as it removes almost all the differences you'll see in browsers when you start styling a page.
One of the sites I reviewed before writing this had a body rule to reset margins and padding to 0, and then went on to reset again them on 8 sub-elements that didn't need it. They also applied other rules to elements where the parent element already had the rule.
This not only wastes space, but the browser has to apply and re-apply all these rules.
The process I use when writing CSS is to apply a rule and then check to see if this rule applies to all other elements within the same container. If it is, then the rule can be moved to the container element.
For example, if you have a menu item where you apply
It is sometimes better to apply a rule to a container element and override it in a one of its children, than apply the same rule to most of the children.
By repeating this process common rules tend to float to less specific selectors at the top of the document tree.
Westciv has a article that explains inheritance.
4. Using CSS shorthand.
Taken from an NZ site, here is the body tag:
This could be better expressed thus:
And another:
This could be more simply expressed as:
These savings are on top of any white-space removal. I'd estimate that the size of the CSS file could be cut in half for a saving of 28k.
4. Avoiding long chains of selectors
These take up more space and take a lot longer to process in the browser.
5. Careful layout of the HTML.
We use a small number of container divs (some of these to work around browser bugs), and keep the selectors to access elements as succinct as possible. We don't use lots of CSS classes, instead using selectors on parent elements to target particular things.
An example is in our left-hand menu area. The left menu is positioned with a div with the id
If you look at the code though, you'll see the padding in all menus is applied via one rule:
I've not got into a great deal of detail on these, so I'm happy to answer any specific questions via comments.
We use gzip compression on the site, so the served filesize is only 6k, but there are other techniques I used to get the initial file size down.
It could be argued that such optimisations are pointless, because any improvements are swamped by the amount of time it takes for the content to traverse the internet. Some prefer maintainability and readability over optimisation. This is true to a point, but only on broadband. We still have a lot of dial-up in New Zealand, and in these cases the speed of the connection is the bottleneck, not the time taken to travel over the net.
The other issues are performance and cost. If you reduce the size and count of files your servers will be able to deliver more requests. If your traffic is metered then any reduction in size saves money. If you are unconvinced read the interview with Mike Davidson regarding the ESPN relaunch.
My aim is to get the HTML and CSS to the browser as fast as possible so that something can be displayed to the user. The load times on pages has a direct effect on the user's perception of quality.
Here are some of the techniques:
1. Using one file.
This reduces the number of server requests (which speeds things up) and ensures that the browser gets everything it needs at once.
2. Reduce white-space.
All rules in our css file are one line each, and there is minimal other white-space. Even though compression will reduce strings of white-space down to one character, stripping this out first ensures that the compression runs faster (fewer characters to process) and that redundant white-space does not have to be decompressed on the browser side. Prior to moving to a Mac I used to use TopSyle Pro which has some tools to convert a more readable version into something smaller, simply by optimsing white-space and some rules. I took a couple of CSS files from major NZ sites and ran them through cleancss to see what sort of savings could be made.
The first site serves a total of 400k on the home page of which 108k is CSS. This could be reduced by 25k with simple optimisations.
The second site serves a total of 507k on the home page of which 56k is CSS. This could be reduced by 28% for a 14k saving.
John at projectx did a more detailed analysis of the top NZ home pages and Government sites using the yslow benchmarks. Interesting reading.
3. Use CSS inheritance
I start all my CSS files this way.
*{font-size:100%;margin:0;padding:0;}This rule resets all elements to no margin, no padding. (The font-size is required to sort out some rendering issues in Internet Explorer when using ems.)
It is a good place to start styling as it removes almost all the differences you'll see in browsers when you start styling a page.
One of the sites I reviewed before writing this had a body rule to reset margins and padding to 0, and then went on to reset again them on 8 sub-elements that didn't need it. They also applied other rules to elements where the parent element already had the rule.
This not only wastes space, but the browser has to apply and re-apply all these rules.
The process I use when writing CSS is to apply a rule and then check to see if this rule applies to all other elements within the same container. If it is, then the rule can be moved to the container element.
For example, if you have a menu item where you apply
{font-size:10px; color:#000} to a <p> and and <li>. The color element can probably be moved to the body element, especially if that is the default for text on the site. The font-size can probably be moved to a div that contains the other two elements.It is sometimes better to apply a rule to a container element and override it in a one of its children, than apply the same rule to most of the children.
By repeating this process common rules tend to float to less specific selectors at the top of the document tree.
Westciv has a article that explains inheritance.
4. Using CSS shorthand.
Taken from an NZ site, here is the body tag:
body{
font-family:Verdana, Arial, Helvetica, sans-serif;
font-size:10px;
color: #333;
margin: 0px;
padding: 0px;
line-height: 130%;
margin-bottom:0px;
font-size: 100%;
background-color: #FFF;
background-repeat:repeat-y;
background-position:center;
background-image:url(/body.gif);
}
This could be better expressed thus:
body{
font:10px/1.3 Verdana, Arial, Helvetica, sans-serif;
color:#333;
margin:0px;
padding:0px;
background:#FFF center top url(/body.gif) repeat-y;
}
And another:
#rule{
padding-left:12px;
padding-top:10px;
padding-right:12px;
padding-bottom:10px;
}
This could be more simply expressed as:
#rule{padding:10px;12px}These savings are on top of any white-space removal. I'd estimate that the size of the CSS file could be cut in half for a saving of 28k.
4. Avoiding long chains of selectors
#side #menu ul.menu li.selected{rules}These take up more space and take a lot longer to process in the browser.
5. Careful layout of the HTML.
We use a small number of container divs (some of these to work around browser bugs), and keep the selectors to access elements as succinct as possible. We don't use lots of CSS classes, instead using selectors on parent elements to target particular things.
An example is in our left-hand menu area. The left menu is positioned with a div with the id
#sn. We can access the main menu with simple rules like #sn li.If you look at the code though, you'll see the padding in all menus is applied via one rule:
li {padding-bottom:4px;}, an example of inheritance.I've not got into a great deal of detail on these, so I'm happy to answer any specific questions via comments.
Subscribe to:
Comments (Atom)